This is my reflective diary for Component 6 of the assessment for MSc module Data Management Fundamentals. The brief was to map and model a NoSQL database for a time series dataset of air pollution readings in Bristol from 1993 to 2023. My mark for this module was 86%.
Introduction
For Component 6, I used the same air quality dataset, modelling and mapping one of its stations in a NoSQL database. I designed a model, cropped and cleaned the data, and built a MongoDB database into which I imported and queried the data.
I decided to use the opportunity to try different tools, so I undertook various parts of the task using Python, PyMongo, JSON, MongoDB Atlas, MongoDB Compass, and Hackolade.
Component 6 enabled me to build on my existing learning and explore the differences between relational and NoSQL databases, offering valuable experience in alternative ways of structuring and managing data that I had never encountered before.
Reflection
Data modelling
Because of the nature of the dataset, I decided that a timeseries database would be most appropriate, and chose MongoDB. While it was not always intended to be a specialised timeseries database, MongoDB has offered this functionality since 2021, bringing benefits including optimised querying and storage (Alessia, 2023).
During Component 5, I noted that the SQL queries returned more non-null data from Station 452 (AURN St Pauls) than any other. As such, I chose to model Station 452 for the NoSQL task because I felt that the query results may be more interesting. I chose to select 5,000 readings as a sample of the 73,495 total from Station 452.
I used Hackolade to design my NoSQL model, structuring the data in three collections: constituency, reading, and metadata_schema.
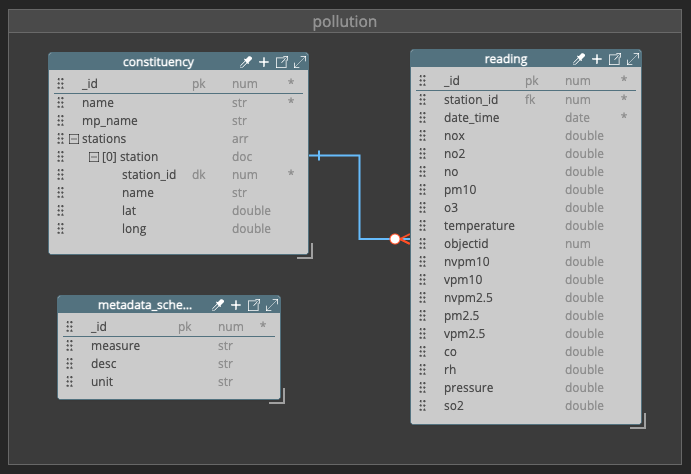
I chose to model station as an embedded subdocument inside constituency, which reflects best practice when modelling a MongoDB schema (Hussain, 2022) because:
- One constituency can have zero-to-many stations but is unlikely to grow unmanageably.
- One station belongs to one constituency only so does not need to have a relationship with other documents.
- Station and constituency data is relatively static.
- Station data is likely to be queried with constituency data so should be stored together.
In contrast, I modelled reading as a separate collection (referenced, not embedded), to avoid document bloat; as a timeseries collection, it has the potential to grow rapidly so embedding in another document would be unsuitable
I initially modelled station as an array but corrected the error and changed it to an object (i.e. a subdocument) of arrays.
I forward engineered my model from Hackolade into MongoDB.
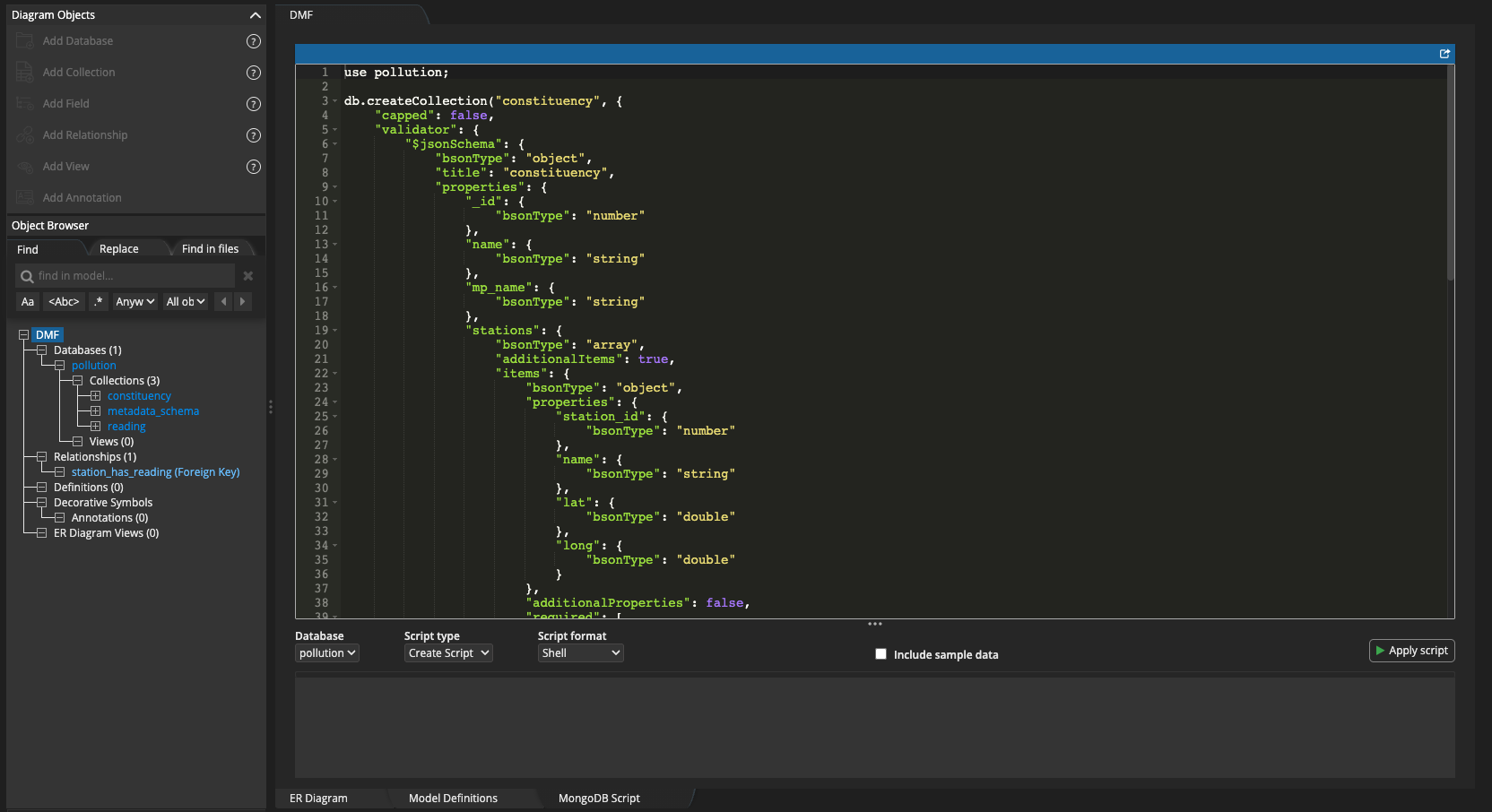
Data import
Because I was modelling just one station, I decided to use the opportunity to write a small JSON document, so I manually inputted the constituency and its embedded station into Atlas.
Before importing the reading data, I adapted my Python script from Component 3 to crop and clean it. I filtered to Station 452, renamed the columns and removed outliers. I randomly selected 5,000 rows as a manageable sample size. Random selection ensured that it was representative of the dataset. I also converted NaN values to None in Python, so that MongoDB could correctly interpret them as null during import (Hadzhiev, 2024).
The import process resulted in some key learning. I followed a MongoDB tutorial (Ranjan, n.d.) to connect to my database and use PyMongo to import CSV data. However, upon running my script I realised that the tutorial was designed to show users how to import one document, not the 5,000 created from my CSV file. My import took over three minutes because every individual line was run using insert_one(); in future I will use an alternative approach such as batch-importing using insert_many(). Alternatively, I could explore other tools to find a more efficient method than reading from a CSV, then writing, then importing.
Another issue was that the import initially failed due to an incompatible datetime format. I tried to use strptime to convert to valid JSON, but I was unable to find a suitable solution. I asked ChatGPT, which suggesting using dateutil and the code provided resolved the issue (OpenAI, 2025).
Compass preview of imported data
To further improve my database, I would also need to import the metadata.
Queries
Whilst querying my MongoDB database, I discovered that numerical data had been imported as strings, preventing me from performing calculations; I had incorrectly assumed that forward engineering from Hackolade would enforce the datatypes from my model.
To avoid retracing my steps and redoing my work, I decided to leave the data in the state that it was imported. However, according to Janwa (2024), importing all data as strings is a common issue and it is possible to covert after import, so this is an alternative approach that I would take in future.
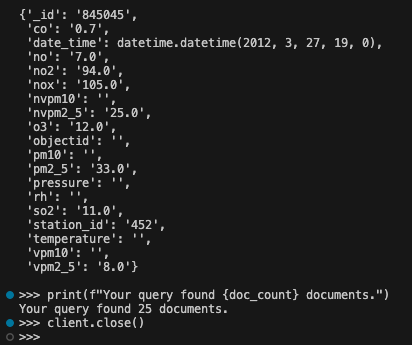
I was still able to run an equality query using PyMongo. I filtered my data to all records where SO2 is equal to “11.0”, which returned 25 documents.
To gain experience in another tool, I learnt how to build a pipeline aggregation query in MongoDB Compass, which enabled me to query my data by datetime. I filtered the data to all records from January 2021; Compass returned 29 documents and I checked this in Excel to confirm the accuracy of my pipeline.
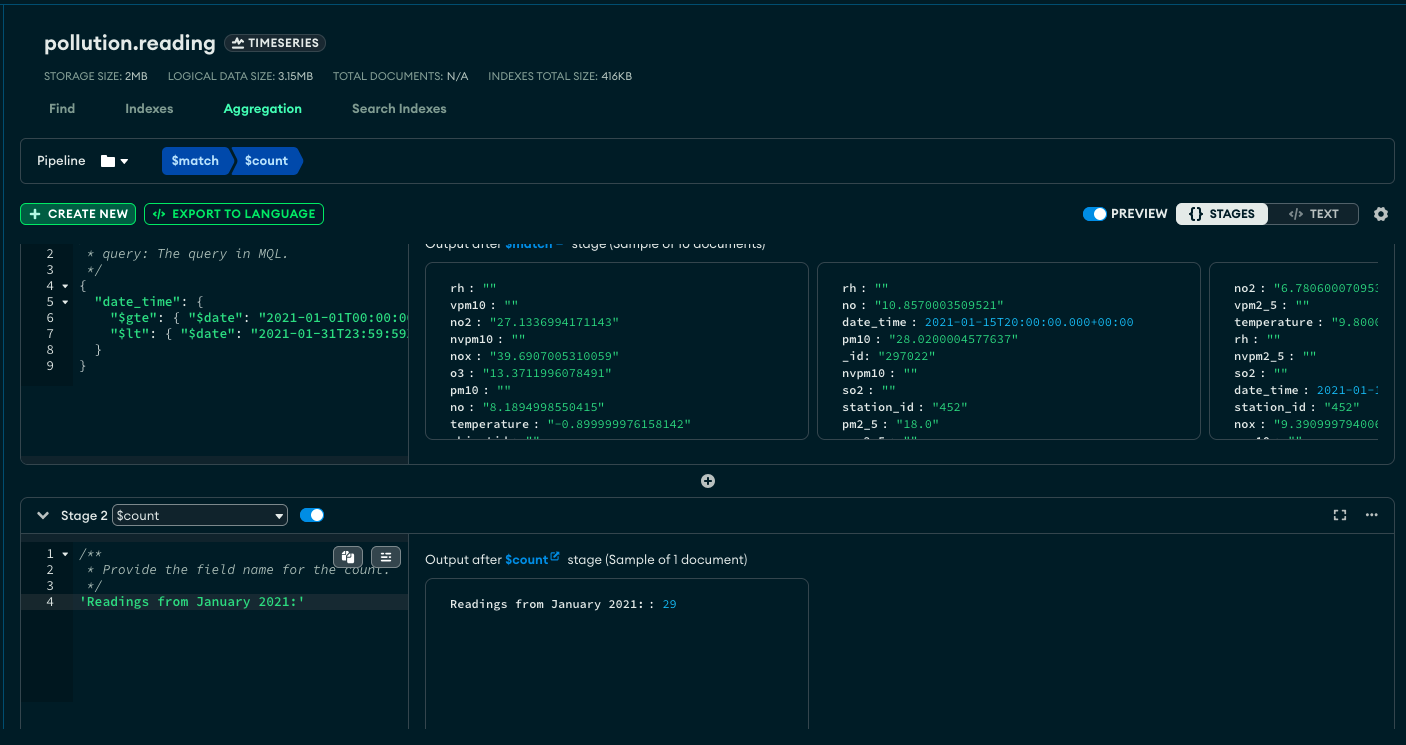
Pipeline in Compass
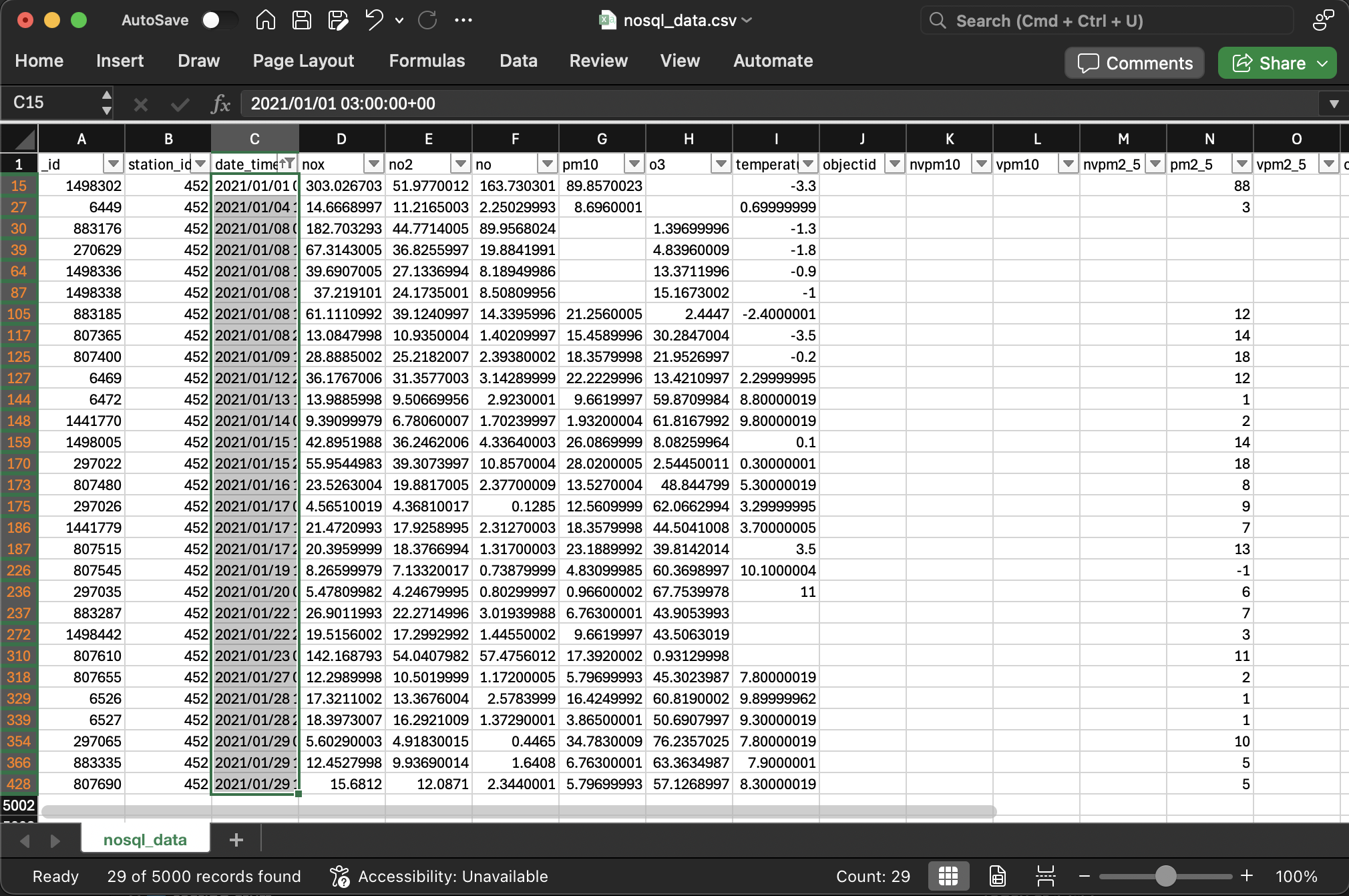
Confirming accuracy in Excel
Relational vs NoSQL databases
Throughout the module, I have gained substantial knowledge of relational and NoSQL databases. I have modelled and mapped data using MySQL and MongoDB, learning about their differences and use cases.
One factor that stood out is the evolution of each over time. Historically there was a distinct divide between RDBMSs and NoSQL ‘with structure and…ACID guarantees on one side, and flexibility and scalability on the other’ (Schiller and Larochelle, 2024). Nowadays, however, the lines between them are becoming blurrier.
Designing the ER model for Component 1 highlighted the features of relational databases, such as their structured nature and commitment to data integrity. Next I developed my MongoDB database and learnt about NoSQL’s flexibility and suitability for storing and querying big, unstructured data (Tomar, 2025).
Evidently, the suitability of different databases depends on the use case, and modern developers are seeking to develop solutions that offer “the best of both worlds”. For example, as discussed by Toiba (2023), there are now distributed relational databases offering flexibility and performance alongside ACID compliance.
Having used both relational and NoSQL databases to store and query the air pollution dataset, I feel that NoSQL is more suited to this use case – particularly thanks to MongoDB’s timeseries functionality. A MongoDB timeseries collection can handle large volumes of data, which may scale very quickly, and offers ‘performance benefits including improved query efficiency and reduced disk usage’ (Alessia 2023).
Conclusion
I found this part of the assignment to be an enjoyable opportunity to independently learn about a topic with which I was completely unfamiliar. I am confident now that I understand the differences between relational NoSQL databases and when to use each. It was also an enjoyable challenge to learn about MongoDB and its document model, and I would feel well-equipped to model a similar dataset in future.
Word count: 1199
Bibliography
Alessia, P. (2023) Time series with MongoDB [blog]. 5 October. Available from: https://medium.com/data-reply-it-datatech/time-series-with-mongodb-dd60f8d6acd6 [Accessed 19 April 2025].
Chen, J. and Pope, E. (no date) MongoDB CRUD Operations in Python [course]. Available from: https://learn.mongodb.com/courses/mongodb-crud-operations-in-python [Accessed 22 April 2025].
Hadzhiev, B. (2024) How to Convert JSON NULL values to None using Python [tutorial]. Available from: https://bobbyhadz.com/blog/python-convert-json-null-to-none [Accessed 22 April 2025].
Hussain, A. (2022) MongoDB Schema Design Anti-patterns in a Nutshell [blog]. 24 February. Available from: https://medium.com/@ayazhussainbs/mongodb-schema-design-anti-patterns-in-a-nutshell-fbd0dfe0d416 [Accessed 15 April 2025].
Janwa, O. (2024) Importing CSV Files into MongoDB: A Comprehensive Guide [tutorial]. Available from: https://www.datarisy.com/blog/importing-csv-files-into-mongodb-a-comprehensive-guide/ [Accessed 22 April 2025].
OpenAI (2025) ChatGPT. ChatGPT response to request for advice in converting datetime format. Available from https://chatgpt.com/share/68080556-3c60-8010-9106-4aedd77bb9b6 [Accessed 22 April 2025].
Palmer, B. (2014) Pandas DataFrame cheat sheet and the Python v R debate [blog]. 5 January. Available from: https://markthegraph.blogspot.com/2014/01/pandas-dataframe-cheat-sheet-and-python.html [Accessed 21 April 2025].
Ranjan, S. (no date) Importing CSV Data into MongoDB [video]. Available from: https://learn.mongodb.com/learn/course/importing-csv-data-into-mongodb/ [Accessed 22 April 2025].
Schiller, R.J. and Larochelle, D. (2024) Data Engineering Best Practices [online]. Birmingham: Packt Publishing. [Accessed 30 April 2025].
Toiba, M. (2023) NoSQL vs. relational: Which database should you use for your app? [blog]. 17 January. Available from: https://devblogs.microsoft.com/cosmosdb/nosql-vs-relational-which-database-should-you-use-for-your-app/ [Accessed 30 April 2025].
Tomar, J. (2025) The Ultimate Battle: MongoDB vs SQL – Top Differences [2025] [blog]. 31 January. Available from: https://www.guvi.in/blog/mongodb-vs-sql-top-differences/ [Accessed 29 April 2025].