import pandas as pd
from supabase import create_client
from pathlib import Path
import os
import sys
from dotenv import load_dotenv
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
import seaborn as sns
colours = sns.color_palette("Set2")
import random
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
pd.options.mode.chained_assignment = None
project_root = os.path.abspath('..')
if project_root not in sys.path:
sys.path.insert(0, project_root)
from eda_utils import add_gbp_columns, get_longest_values, print_in_rows, check_names, check_overlap, clean_start_of_text, update_join_table
from stats_builder import make_summary_df, calculate_stats, make_calculated_df, format_stats, format_df
from plots_builder import make_bar_chart
from utils import get_table_from_supabase, build_relationship_cols, build_financial_history, add_grant_statistics
from data_importer import pipe_to_supabase
#get keys from env
load_dotenv()
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_KEY")Exploratory Data Analysis
Setup
Retrieving Data from Supabase and Building Dataframes
I will connect to Supabase and retrieve all records, in order to start building my analysis dataframes. I will create one dataframe for funder information, and another for grants and recipients information.
#get tables and build dataframes
tables = ["funders", "causes", "areas", "beneficiaries", "grants",
"funder_causes", "funder_areas", "funder_beneficiaries", "funder_grants",
"financials", "funder_financials"]
for table in tables:
globals()[table] = get_table_from_supabase(url, key, table)
#get recipients with filter
recipients = get_table_from_supabase(url, key, "recipients", batch_size=50, filter_recipients=True)
all_recipient_ids = set(recipients["recipient_id"].unique())
#get and filter recipient join tables
recipient_join_tables = ["recipient_grants", "recipient_areas", "recipient_beneficiaries", "recipient_causes"]
for table in recipient_join_tables:
df = get_table_from_supabase(url, key, table)
globals()[table] = df[df["recipient_id"].isin(all_recipient_ids)]The Funders Dataframe
Main Table
funders_df = funders.copy()
#define table relationships for funders
funder_rels = [
{
"join_table": funder_causes,
"lookup_table": causes,
"key": "cause_id",
"value_col": "cause_name",
"result_col": "causes"
},
{
"join_table": funder_areas,
"lookup_table": areas,
"key": "area_id",
"value_col": "area_name",
"result_col": "areas"
},
{
"join_table": funder_beneficiaries,
"lookup_table": beneficiaries,
"key": "ben_id",
"value_col": "ben_name",
"result_col": "beneficiaries"
}
]
#add relationship columns
funders_df = build_relationship_cols(funders_df, "registered_num", funder_rels)
#add grant statistics columns
funders_df = add_grant_statistics(funders_df, "registered_num", funder_grants, grants)
#round to 2 decimal places
funders_df = funders_df.round(2)
pd.set_option("display.float_format", "{:.2f}".format)
#format financial columns
float_cols = ["income_latest", "expenditure_latest", "total_given", "avg_grant", "median_grant"]
for col in float_cols:
if col in funders_df.columns:
funders_df[col + "_gbp"] = funders_df[col].apply(add_gbp_columns)Financial History Table
funders_df = build_financial_history(funders_df, "registered_num", funder_financials, financials)The List Entries
#get list entries
list_entries = get_table_from_supabase(url, key, "list_entries")
funder_list = get_table_from_supabase(url, key, "funder_list")
list_with_info = funder_list.merge(list_entries, on="list_id")
#get list of entries for each funder
list_grouped = list_with_info.groupby("registered_num")["list_info"].apply(list).reset_index()
list_grouped.columns = ["registered_num", "list_entries"]
#merge with funders and replace nans
funders_df = funders_df.merge(list_grouped, on="registered_num", how="left")
funders_df["list_entries"] = funders_df["list_entries"].apply(lambda x: x if isinstance(x, list) else [])#extend column view, sort and preview funders
pd.set_option("display.max_columns", 100)
funders_df = funders_df.sort_values("total_given_gbp", ascending=False)
funders_df.head()| registered_num | name | website | activities | objectives | income_latest | expenditure_latest | objectives_activities | achievements_performance | grant_policy | is_potential_sbf | is_on_list | is_nua | causes | areas | beneficiaries | num_grants | total_given | avg_grant | median_grant | income_latest_gbp | expenditure_latest_gbp | total_given_gbp | avg_grant_gbp | median_grant_gbp | income_history | expenditure_history | list_entries | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 872 | 288086 | FARRER AND CO CHARITABLE TRUST | https://www.farrer.co.uk | THE MAIN PURPOSE OF THE TRUST IS TO APPLY INCO... | IN OR TOWARDS THE GENERAL PURPOSES OF SUCH CHA... | 80569.00 | 78229.00 | None | None | None | False | False | False | [General Charitable Purposes] | [Throughout England And Wales] | [Other Charities Or Voluntary Bodies] | 14 | 97590.14 | 6970.72 | 4000.00 | £80,569.00 | £78,229.00 | £97,590.14 | £6,970.72 | £4,000.00 | {2020: 78285.0, 2021: 52439.0, 2022: 79299.0, ... | {2020: 76431.0, 2021: 61395.0, 2022: 76795.0, ... | [] |
| 51 | 1041449 | MIRACLES | https://www.miraclesthecharity.org | MIRACLES IS A CHARITY OFFERING HOPE FOR THOSE ... | THE RELIEF OF POVERTY AND HARDSHIP OF PERSONS ... | 351143.00 | 908121.00 | THE AIMS AND OBJECTS OF MIRACLES REMAIN TO PRO... | THIRTY-ONE YEARS ON SINCE THE LAUNCH OF MIRACL... | None | False | False | False | [General Charitable Purposes, Education/traini... | [Scotland, Europe, Throughout England] | [The General Public/mankind] | 8 | 96073.00 | 12009.12 | 2750.00 | £351,143.00 | £908,121.00 | £96,073.00 | £12,009.12 | £2,750.00 | {2020: 235183.0, 2021: 325035.0, 2022: 303775.... | {2020: 322068.0, 2021: 337276.0, 2022: 274309.... | [] |
| 968 | 526956 | KELSICK'S EDUCATIONAL FOUNDATION | https://www.kelsick.org.uk | TO PROVIDE GRANTS FOR EDUCATIONAL NEEDS TO YOU... | 1)THE PROVISION OF SPECIAL BENEFITS, OF ANY KI... | 411338.00 | 408717.00 | THE OBJECTS OF THE CHARITY ARE:\n1. THE PROVIS... | THE KELSICK'S EDUCATION FOUNDATION CONTINUES T... | THE FOUNDATION INVITES APPLICATIONS FOR GRANTS... | False | False | False | [Education/training] | [Cumbria] | [Children/young People, People With Disabiliti... | 17 | 956424.00 | 56260.24 | 58800.00 | £411,338.00 | £408,717.00 | £956,424.00 | £56,260.24 | £58,800.00 | {2020: 416991.0, 2021: 387390.0, 2022: 407536.... | {2020: 408890.0, 2021: 381641.0, 2022: 382351.... | [] |
| 772 | 260741 | A P TAYLOR TRUST | https://www.aptaylortrust.org.uk | THE YEARLY INCOME OF THE FUND PROVIDED BY THE ... | FUND FOR THE USE OF THE INHABITANTS OF THE PAR... | 111430.00 | 136811.00 | THE YEARLY INCOME OF THE FUND PROVIDED BY THE ... | DURING THE YEAR, THE CHARITY CHOSE TO OFFER AD... | DURING THE YEAR, A TOTAL AMOUNT OF £36,450 WAS... | False | False | False | [General Charitable Purposes, The Advancement ... | [Hillingdon, Greater London] | [Children/young People, Elderly/old People, Pe... | 75 | 95240.00 | 1269.87 | 300.00 | £111,430.00 | £136,811.00 | £95,240.00 | £1,269.87 | £300.00 | {2020: 112954.0, 2021: 105886.0, 2022: 98342.0... | {2020: 114393.0, 2021: 124987.0, 2022: 114089.... | [] |
| 806 | 270718 | FRANCIS COALES CHARITABLE FOUNDATION | https://franciscoales.co.uk | TO ASSIST WITH GRANTS FOR THE STRUCTURAL REPAI... | TO PROVIDE FUNDS DIRECTLY OR BY WAY OF GRANT O... | 117420.00 | 118765.00 | None | None | None | False | False | False | [Environment/conservation/heritage] | [Buckinghamshire, Hertfordshire, Northamptonsh... | [Other Defined Groups] | 3 | 93953.00 | 31317.67 | 5000.00 | £117,420.00 | £118,765.00 | £93,953.00 | £31,317.67 | £5,000.00 | {2020: 111553.0, 2021: 134468.0, 2022: 149302.... | {2020: 129452.0, 2021: 132270.0, 2022: 120004.... | [] |
#get checkpoint folder
# checkpoint_folder = Path("./6.1_checkpoints/")
#create checkpoint - save df to pickle
# funders_df.to_pickle(checkpoint_folder / "funders_df.pkl")
# print("Saved funders_df to checkpoint")The Grants Dataframe
Main Table
grants_df = grants.copy()
#ddd funder info
grants_df = grants_df.merge(funder_grants, on="grant_id")
grants_df = grants_df.merge(funders[["registered_num", "name"]], on="registered_num")
grants_df = grants_df.rename(columns={"name": "funder_name", "registered_num": "funder_num"})
#ddd recipient info
grants_df = grants_df.merge(recipient_grants, on="grant_id")
grants_df = grants_df.merge(recipients[["recipient_id", "recipient_name", "recipient_activities"]],
on="recipient_id",
how="left")
#define relationships for recipients
recipient_rels = [
{
"join_table": recipient_areas,
"lookup_table": areas,
"key": "area_id",
"value_col": "area_name",
"result_col": "recipient_areas"
},
{
"join_table": recipient_causes,
"lookup_table": causes,
"key": "cause_id",
"value_col": "cause_name",
"result_col": "recipient_causes"
},
{
"join_table": recipient_beneficiaries,
"lookup_table": beneficiaries,
"key": "ben_id",
"value_col": "ben_name",
"result_col": "recipient_beneficiaries"
}
]
#add relationship columns
grants_df = build_relationship_cols(grants_df, "recipient_id", recipient_rels)
#add source of grant
grants_df["source"] = grants_df["grant_id"].apply(lambda x: "Accounts" if str(x).startswith("2") else "360Giving")
#round to 2 decimal places
grants_df = grants_df.round(2)
#format financial columns
grants_df["amount_gbp"] = grants_df["amount"].apply(add_gbp_columns)#sort and preview grants
grants_df = grants_df.sort_values("grant_title", ascending=True)
grants_df.head()| grant_title | grant_desc | amount | year | grant_id | source | funder_num | funder_grants_id | funder_name | recipient_id | recipient_grants_id | recipient_name | recipient_activities | recipient_areas | recipient_causes | recipient_beneficiaries | amount_gbp | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 24592 | "A BLUE NEW DEAL FOR UK COSTAL COMMUNITIES" PR... | TOWARDS THE COSTS OF THE 'BLUE NEW DEAL', WHIC... | 90000.00 | 2014 | 360G-Ellerman-15189 | 360Giving | 263207 | 44987 | JOHN ELLERMAN FOUNDATION | 1055254 | 43799 | NEW ECONOMICS FOUNDATION | NEF AIMS TO MAXIMISE WELL-BEING AND SOCIAL JUS... | [Throughout England And Wales] | [Education/training, Economic/community Develo... | [The General Public/mankind] | £90,000.00 |
| 29639 | "BEFRIENDING COFFEE CLUB" | THE BEFRIENDING COFFEE CLUB WAS A TWO-YEAR PRO... | 27313.00 | 2017 | 360G-PeoplesHealthTrust-2017_5 | 360Giving | 1125537 | 41014 | PEOPLE'S HEALTH TRUST | 1166949 | 39824 | SANDWELL AFRICAN WOMEN ASSOCIATION | 1. ADVICE & SUPPORT\rA) GENERAL HELP WITH CLAI... | [Sandwell, West Midlands] | [General Charitable Purposes, The Advancement ... | [Children/young People, Elderly/old People, Pe... | £27,313.00 |
| 29462 | "BETTER LIVES" | THIS TWO-YEAR PROJECT DELIVERED ACTIVITIES AND... | 43982.00 | 2017 | 360G-PeoplesHealthTrust-2017_103 | 360Giving | 1125537 | 40917 | PEOPLE'S HEALTH TRUST | 1093240 | 39727 | SOUTHEND CARERS | TO PROVIDE INFORMATION, ADVICE AND SUPPORT TO ... | [Southend-on-sea, Essex] | [Disability, Other Charitable Purposes] | [Children/young People, Elderly/old People, Pe... | £43,982.00 |
| 24854 | "BLUE PANET II - TURNING VIEWRS INTO CHAMPIONS... | TOWARDS A JOINT INITIATIVE BY MCS, GREENPEACE ... | 6000.00 | 2017 | 360G-Ellerman-17137 | 360Giving | 263207 | 45242 | JOHN ELLERMAN FOUNDATION | 1004005 | 44054 | MARINE CONSERVATION SOCIETY | THE MARINE CONSERVATION SOCIETY FIGHTS FOR THE... | [Scotland, Europe, Turks And Caicos Islands, N... | [Education/training, Arts/culture/heritage/sci... | [The General Public/mankind] | £6,000.00 |
| 25044 | "BODY VESSEL CLAY – WOMEN RETHINKING CERAMICS"... | "BODY VESSEL CLAY – WOMEN RETHINKING CERAMICS"... | 30000.00 | 2021 | 360G-Ellerman-18459 | 360Giving | 263207 | 45468 | JOHN ELLERMAN FOUNDATION | 1123081 | 44280 | BULLDOG TRUST LIMITED | THE TRUST PROVIDES FINANCIAL AND ADVISORY ASSI... | [Throughout England And Wales] | [General Charitable Purposes, Arts/culture/her... | [The General Public/mankind] | £30,000.00 |
#create checkpoint - save df to pickle
# grants_df.to_pickle(checkpoint_folder / "grants_df.pkl")
# print("Saved grants_df to checkpoint")Retrieving Data from Checkpoints
#get checkpoint folder
checkpoint_folder = Path("./6.1_checkpoints/")
#get checkpoint
funders_df = pd.read_pickle(checkpoint_folder / "funders_df.pkl")
grants_df = pd.read_pickle(checkpoint_folder / "grants_df.pkl")Data Quality
1. Missingness
I will view the structure of each dataframe to check for missing data and confirm that datatypes are correct.
Analysis of Missingness in Funders Dataframe
funders_df.info()<class 'pandas.core.frame.DataFrame'>
Index: 996 entries, 820 to 995
Data columns (total 28 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 registered_num 996 non-null object
1 name 996 non-null object
2 website 497 non-null object
3 activities 991 non-null object
4 objectives 996 non-null object
5 income_latest 996 non-null float64
6 expenditure_latest 996 non-null float64
7 objectives_activities 229 non-null object
8 achievements_performance 193 non-null object
9 grant_policy 52 non-null object
10 is_potential_sbf 996 non-null bool
11 is_on_list 996 non-null bool
12 is_nua 996 non-null bool
13 causes 996 non-null object
14 areas 996 non-null object
15 beneficiaries 996 non-null object
16 num_grants 309 non-null Int64
17 total_given 309 non-null float64
18 avg_grant 309 non-null float64
19 median_grant 309 non-null float64
20 income_latest_gbp 996 non-null object
21 expenditure_latest_gbp 996 non-null object
22 total_given_gbp 996 non-null object
23 avg_grant_gbp 996 non-null object
24 median_grant_gbp 996 non-null object
25 income_history 996 non-null object
26 expenditure_history 996 non-null object
27 list_entries 996 non-null object
dtypes: Int64(1), bool(3), float64(5), object(19)
memory usage: 206.2+ KB#missing activities - check manually
missing_activities = funders_df[funders_df["activities"].isna()]["registered_num"].tolist()
print(missing_activities)['1207622', '1203444', '1203389', '1203342', '1204043']#missing sections - check proportion of funders with sections extracted from accounts
has_sections = funders_df[
funders_df["objectives_activities"].notna() |
funders_df["achievements_performance"].notna() |
funders_df["grant_policy"].notna()
]
has_sections_total = len(has_sections)
has_sections_proportion = has_sections_total / 996
print(f"Funders with accessible accounts: 327")
print(f"Funders with extracted sections: {has_sections_total}")
print(f"Proportion of funders with sections: {has_sections_proportion:.2%}")Funders with accessible accounts: 327
Funders with extracted sections: 242
Proportion of funders with sections: 24.30%#missing classifications - check manually
classifications = ["causes", "areas", "beneficiaries"]
for classification in classifications:
missing = funders_df[funders_df[classification].apply(lambda x: len(x) == 0)]
print(f"{len(missing)} ({len(missing)/len(funders_df)*100:.1f}%) missing from {classification}")
print(f"Registered numbers: {missing['registered_num'].tolist()}\n")0 (0.0%) missing from causes
Registered numbers: []
0 (0.0%) missing from areas
Registered numbers: []
7 (0.7%) missing from beneficiaries
Registered numbers: ['1180365', '1203444', '1180966', '1181515', '1174620', '1191072', '1166657']
Exploration of Findings from Missingness Analysis (Funders)
There are five funders in the database with empty activities. I have checked the Charity Commission website and it does appear that these funders have simply not declared any activities. They are all relatively new having submitted only one set of accounts. The activities_objectives column has not been populated for any of these funders, which is unfortunate as this could have provided a further source of information. One of these funders has a website so, if I am able to achieve my stretch target of scraping websites, this may offer details (although at the time of writing, the website does not exist).
It is expected that a significant proportion of funders would not have a website, and no action is required to address this.
Checking missing classifications shows that the dataset is almost entirely complete in this regard; just seven funders are missing beneficiaries, and having checked the Charity Commission website, it appears that these funders have not declared any beneficiaries. This is such a small proportion of the dataset that I am not concerned about its impact on analysis and embeddings.
Problem with Accounts
My database building scripts (for PDFs) have a serious limitation as I am unable to scrape the Charity Commission website for accounts where the page contains JavaScript. The older pages, which are basic HTML, are accessible but the newer ones are not, and I am unable to tell which charities have been updated to the new system until the script attempts to scrape them and fails. Having built the database, I can now see from the print statements that 327 funders have accessible accounts, representing 32.8% of the 996 funders in the sample. My calculations above show that the required sections have been extracted from accounts for 24.4% of funders - varying from 52 funders with grant_policy, to 193 funders with achievements_peformance and 229 funders with objectives_activities.
Analysis of Missingness in Grants Dataframe
grants_df.info()<class 'pandas.core.frame.DataFrame'>
Index: 33152 entries, 6305 to 33151
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 grant_title 18116 non-null object
1 grant_desc 18116 non-null object
2 amount 33106 non-null float64
3 year 33152 non-null int64
4 grant_id 33152 non-null object
5 source 33152 non-null object
6 funder_num 33152 non-null object
7 funder_grants_id 33152 non-null int64
8 funder_name 33152 non-null object
9 recipient_id 33152 non-null object
10 recipient_grants_id 33152 non-null int64
11 recipient_name 33152 non-null object
12 recipient_activities 15829 non-null object
13 recipient_areas 33152 non-null object
14 recipient_causes 33152 non-null object
15 recipient_beneficiaries 33152 non-null object
16 amount_gbp 33152 non-null object
dtypes: float64(1), int64(3), object(13)
memory usage: 4.6+ MB#missing grant title and description - check numbers per source
missing_by_source = grants_df.groupby("source").agg({
"grant_title": lambda x: x.isna().sum(),
"grant_desc": lambda x: x.isna().sum(),
"grant_id": "count"
}).rename(columns={"grant_id": "total_grants", "grant_title": "missing_title", "grant_desc": "missing_desc"})
print(missing_by_source) missing_title missing_desc total_grants
source
360Giving 0 0 18116
Accounts 15036 15036 15036#missing grant amounts - spotcheck manually
missing_amounts = grants_df[grants_df["amount"].isna()]["funder_num"].tolist()
print(missing_amounts)['217929', '217929', '217929', '217929', '217929', '217929', '217929', '217929', '252222', '1052958', '525834', '244053', '503384', '503384', '503384', '503384', '503384', '503384', '503384', '503384', '503384', '503384', '503384', '503384', '219289', '1017255', '803301', '217929', '217929', '217929', '237048', '237048', '237048', '237048', '237048', '237048', '237048', '237048', '237048', '237048', '291363', '291363', '291363', '291363', '268745', '1059451']#missing recipient activities - compare by source
missing_recips = grants_df["recipient_activities"].isna().sum()
accounts_recips = grants_df[
(grants_df["source"] == "Accounts") &
(grants_df["recipient_activities"].isna())
]
missing_360g = grants_df[
(grants_df["source"] == "360Giving") &
(grants_df["recipient_activities"].isna())
]
print(f"Grants extracted from accounts: {len(accounts_recips):,} ({len(accounts_recips)/missing_recips*100:.1f}%)")
print(f"360Giving recipients with missing activities: {len(missing_360g):,} ({len(missing_360g)/missing_recips*100:.1f}%)")Grants extracted from accounts: 11,491 (66.3%)
360Giving recipients with missing activities: 5,832 (33.7%)Exploration of Findings from Missingness Analysis (Grants)
There are 33,147 rows in the dataframe, 287 more than the number of unique grants as some grants are given to multiple recipients. The deduplication script in stats_builder.py ensures that the value of each grant has only been counted once for the purpose of the summary/calculated statistics.
I have explored the missing data from grant_title and grant_desc to check that only grants extracted from accounts are missing these fields. This was to be expected as these details are not available for the grants from accounts; the figures above confirm that every grant from the 360Giving API is complete with a title and description.
Of the 32,815 grants in the database, 46 (0.14%) are missing amount. I have performed a spot-check of 12 grants (25%), which suggests that these are genuine extraction errors from funder accounts rather than systematic issues. I have decided to keep these 46 grants in the database as they still provide valuable information about funder-recipient relationships and giving patterns, and such a small number of missing amounts is not likely to affect analyses/models.
I also explored the 17,318 rows in grants_df with missing recipient_activities. Null values in this column are to be expected for recipients that are added following extraction from PDFs, which accounts for 11,486 (66.3%). The remaining 5,832 (33.7%) null values - which are present within records added to the database by the 360Giving API - can be explained by: - Charities that have been removed from the Charity Commission, e.g. if they have closed down - Registered charities that simply do not declare their activities (as present in 5 records in funders_df) - Where abnormalities are evident in registered_num. For example, the RSPB is identified in the 360Giving API by 207076 & SC037654 - its registered numbers for both the Charity Commission of England & Wales and the Office of the Scottish Charity Regulator. My database builder script was unable to match on 207076 & SC037654 as registered_num.
2. Word Counts
I will check the lengths of the shortest and longest text entries, to ensure that they have been imported correctly and are not too short or long for unexpected reasons. Many funders provide very short explanations of their activities/objectives etc., such as simply “grant-giving” which is just one word - so this would not be abnormal. I will confirm that particularly long entries are not corrupted or the result of multiple documents being combined accidentally.
Analysis of Word Counts in Funders Dataframe
#check word counts for text columns in funders df
funders_text_cols = ["activities", "objectives", "objectives_activities", "achievements_performance", "grant_policy"]
#create columns
for col in funders_text_cols:
funders_df[f"word_count_{col}"] = funders_df[col].str.split().str.len()
for col in funders_text_cols:
print(f"{col.upper()}")
print(f"{'_'*30}\n")
word_count_col = f"word_count_{col}"
not_nas = funders_df[funders_df[word_count_col].notna()]
#get minimums and maximums for each text column
if len(not_nas) > 0:
min_idx = not_nas[word_count_col].idxmin()
max_idx = not_nas[word_count_col].idxmax()
examples = funders_df.loc[[min_idx, max_idx], ["registered_num", "name", word_count_col, col]]
examples.index = ["Minimum", "Maximum"]
display(examples)
else:
print("No data available\n")ACTIVITIES
______________________________
| registered_num | name | word_count_activities | activities | |
|---|---|---|---|---|
| Minimum | 277767 | WANSTEAD HIGH SCHOOL PARENT-TEACHER ASSOCIATION | 1.00 | FUNDRAISING |
| Maximum | 217929 | BARTON UNDER NEEDWOOD AND DUNSTALL KEY TRUST | 76.00 | TO PAY THE MINISTER OF THE CHURCH OF ST JAMES ... |
OBJECTIVES
______________________________
| registered_num | name | word_count_objectives | objectives | |
|---|---|---|---|---|
| Minimum | 213077 | EPPING AND THEYDON GARNON CHARITIES | 2 | SEE CONSTITUENTS |
| Maximum | 1104413 | INSPIRE HOUNSLOW | 524 | 3. THE OBJECTS OF THE COMPANY (THE "OBJECTS") ... |
OBJECTIVES_ACTIVITIES
______________________________
| registered_num | name | word_count_objectives_activities | objectives_activities | |
|---|---|---|---|---|
| Minimum | 1030939 | TESLER FOUNDATION | 16.00 | OBJECTIVES AND AIMS THE CHARITY IS GOVERNED BY... |
| Maximum | 263207 | JOHN ELLERMAN FOUNDATION | 5426.00 | TARGET OF CASH + 4% ANNUALLY, NET OF COSTS. A ... |
ACHIEVEMENTS_PERFORMANCE
______________________________
| registered_num | name | word_count_achievements_performance | achievements_performance | |
|---|---|---|---|---|
| Minimum | 802125 | TOMCHEI TORAH CHARITABLE TRUST | 14.00 | CHARITABLE ACTIVITIES DURING THE YEAR THE CHAR... |
| Maximum | 263207 | JOHN ELLERMAN FOUNDATION | 5426.00 | TARGET OF CASH + 4% ANNUALLY, NET OF COSTS. A ... |
GRANT_POLICY
______________________________
| registered_num | name | word_count_grant_policy | grant_policy | |
|---|---|---|---|---|
| Minimum | 1057692 | DOWNEND ROUND TABLE | 8.00 | POLICY ON SOCIAL INVESTMENT INCLUDING PROGRAM ... |
| Maximum | 299918 | C A REDFERN CHARITABLE FOUNDATION | 1181.00 | THE TRUSTEES MEET REGULARLY TO DISCUSS THE MAK... |
Word Counts for Sections Returned from Charity Commission API
#high word counts - check top 10 longest sections from API (to manually check)
long_activities = get_longest_values(funders_df, "word_count_activities", "registered_num")
long_objectives = get_longest_values(funders_df, "word_count_objectives", "registered_num")
api_sections_long = [
("activities", long_activities),
("objectives", long_objectives)
]
for name, longest in api_sections_long:
print(f"Top 10 longest {name}: {longest}")Top 10 longest activities: ['217929', '213077', '207342', '298379', '516301', '1135751', '272671', '1114624', '1197536', '1193970']
Top 10 longest objectives: ['1104413', '310799', '1132994', '229974', '1190948', '1194823', '1094675', '1047947', '1173674', '1147921']#low word counts - count and view short sections from API
api_sections_short = {
"activities": "Short activities sections",
"objectives": "Short objectives sections"
}
for col, title in api_sections_short.items():
funders_df[f"short_{col}_section"] = (
(funders_df[col].str.split().str.len() < 5) &
(funders_df[col].str.upper().str.strip() != "GENERAL CHARITABLE PURPOSES")
)
short_sections = funders_df[funders_df[f"short_{col}_section"]][col].dropna().unique()
print(f"\n{title}: {funders_df[f'short_{col}_section'].sum():,}")
print_in_rows(short_sections, 5)
Short activities sections: 39
A GRANT GIVING TRUST, CHARITABLE PURPOSES, GENERAL CHARITABLE PURPOSES., GRANT MAKING, CHARITABLE GIVING
PROJECTS FOR NEEDY, FUNDRAISING, GRANT MAKING CHARITY, GRANT-MAKING CHARITY, GENERAL CHARITABLE DONATIONS
GRANT GIVING., MAKING GRANTS, GRANT-MAKING, ANIMAL WELFARE, AT THE TRUSTEES DISCRETION.
FUNDING CHARITABLE CAUSES., GRANT GIVING CHARITY, GRANT-MAKING., ASSISTANCE WITH RELIGIOUS EDUCATION, ENCOURAGING CHARITABLE GIVING
ADVANCING ORTHODOX JEWISH FAITH, GRANTS TO ADVANCE EDUCATION., RELIEF OF POOR, HELPING DISADVANTAGED CHILDREN, EDUCATION / TRAINING
NONE, PROVIDING GRANTS, GENERAL CHARITABLE ACTIVITIES, THROUGHOUT ENGLAND AND WALES, NONE UNDERTAKEN
CHARITABLE GRANTS MADE, SUPPORT LOCAL CHARITIES.
Short objectives sections: 15
SEE INDIVIDUAL CONSTITUENTS, GENERAL CHARITABLE PURPOSES., SEE INDIVIDUAL CONSTITUENTS., SEE CONSTITUENTS, FOR CHARITABLE PURPOSES.
ANY CHARITABLE PURPOSE.#low word counts - check activities containing "NONE"
activities_none = funders_df["activities"].str.contains("NONE", na=False)
funders_df[activities_none]| registered_num | name | website | activities | objectives | income_latest | expenditure_latest | objectives_activities | achievements_performance | grant_policy | is_potential_sbf | is_on_list | is_nua | causes | areas | beneficiaries | num_grants | total_given | avg_grant | median_grant | income_latest_gbp | expenditure_latest_gbp | total_given_gbp | avg_grant_gbp | median_grant_gbp | income_history | expenditure_history | list_entries | word_count_activities | word_count_objectives | word_count_objectives_activities | word_count_achievements_performance | word_count_grant_policy | short_activities_section | short_objectives_section | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 355 | 505515 | ALLENDALE EXHIBITION ENDOWMENT | None | NONE | THE INCOME OF THE CHARITY SHALL BE APPLIED BY-... | 24000.00 | 14299.00 | None | None | None | False | False | False | [Education/training] | [Northumberland] | [Children/young People] | <NA> | NaN | NaN | NaN | £24,000.00 | £14,299.00 | {2020: 7044.0, 2021: 4100.0, 2022: 13836.0, 20... | {2020: 7190.0, 2021: 5000.0, 2022: 13083.0, 20... | [] | 1.00 | 111 | NaN | NaN | NaN | True | False | |||
| 367 | 1103709 | MARCIA AND ANDREW BROWN CHARITABLE TRUST | None | NONE UNDERTAKEN | TO BENEFIT SUCH EXCLUSIVELY CHARITABLE PURPOSE... | 304104.00 | 190330.00 | None | None | None | False | False | False | [General Charitable Purposes] | [Throughout England And Wales] | [The General Public/mankind] | <NA> | NaN | NaN | NaN | £304,104.00 | £190,330.00 | {2020: 201144.0, 2021: 400020.0, 2022: 1850115... | {2020: 33618.0, 2021: 63195.0, 2022: 87510.0, ... | [] | 2.00 | 18 | NaN | NaN | NaN | True | False |
Word Counts for Sections Extracted from PDF Accounts
#high word counts - check top 10 longest extracted sections (to manually check)
long_obj_act = get_longest_values(funders_df, "word_count_objectives_activities", "registered_num")
long_ach_perf = get_longest_values(funders_df, "word_count_achievements_performance", "registered_num")
long_grant_policy = get_longest_values(funders_df, "word_count_grant_policy", "registered_num")
accounts_sections_long = [
("objectives_activities", long_obj_act),
("achievements_performance", long_ach_perf),
("grant_policy", long_grant_policy)
]
for name, longest in accounts_sections_long:
print(f"Top 10 longest {name}: {longest}")Top 10 longest objectives_activities: ['263207', '803428', '252892', '213890', '1041449', '296284', '217929', '288068', '299918', '260589']
Top 10 longest achievements_performance: ['263207', '803428', '200198', '213890', '1041449', '217929', '299918', '254532', '296284', '288068']
Top 10 longest grant_policy: ['299918', '1038860', '216308', '288068', '257636', '1026752', '272161', '255281', '226121', '1040778']#low word counts - count and view short sections from accounts
accounts_sections_short = {
"objectives_activities": "Short objectives_activities sections",
"achievements_performance": "Short achievements_performance sections",
"grant_policy": "Short grant_policy sections"
}
for col, title in accounts_sections_short.items():
funders_df[f"short_{col}_section"] = (
(funders_df[col].str.split().str.len() < 20)
)
short_sections = funders_df[funders_df[f"short_{col}_section"]][col].dropna().unique()
print(f"\n{title}: {funders_df[f'short_{col}_section'].sum():,}")
print_in_rows(short_sections, 2)
Short objectives_activities sections: 3
THE TRUSTEES CONTINUALLY CONSIDER THE ONGOING POSITION OF THE FARM LAND, PARTICULARLY IN VIEW OF POSSIBLE DEVELOPMENT., - - - - TOTAL INCOMING RESOURCES 52,119 - 52,119 43,051 __ _ ________ _____ __ ___ ________
OBJECTIVES AND AIMS THE CHARITY IS GOVERNED BY A DEED OF TRUST DATED 21ST FEBRUARY 1992.
Short achievements_performance sections: 1
CHARITABLE ACTIVITIES DURING THE YEAR THE CHARITY MADE CHARITABLE GRANTS TOTALLING £13,374 (2022: £15,530).
Short grant_policy sections: 10
POLICY ON SOCIAL INVESTMENT INCLUDING PROGRAM RELATED INVESTMENT, GRANTS ARE MADE TO CHARITABLE INSTITUTIONS, ORGANIZATIONS AND AUTHORIZED INDIVIDUALS WHICH ACCORD WITH THE OBJECTS OF THE CHARITY.
GRANTS ARE MADE TO CHARITABLE INSTITUTIONS AND ORGANIZATIONS WHICH ACCORD WITH THE OBJECTS OF THE CHARITY.Exploration of Findings from Word Count Analysis (Funders)
Sections from API
Having manually checked the maximum values against their Charity Commission records, I am confident that there are no entries that are concerningly long. The top 10 longest activities are not abnormal; they are just relatively wordy compared to others. I viewed the shortest values (fewer than five words) and concluded that they are acceptable, although I will reassign the values containing “NONE” to N/A to improve the quality of the embedding.
Sections from Accounts
The word count analysis has highlighted that there are numerous issues with the sections that have been extracted from accounts. Many that are too long contain multiple sections, whereas many that are too short have been cut off prematurely. There is also a problem of repetition - the extractor sometimes extracts the same (excessively long) chunk of text for both objectives_activities and achievements_performance, defeating the purpose. Looking at the top 10 shortest and longest has demonstrated that the regex extraction technique employed in the database builder has not worked very well. Rather than rebuilding the entire PDF extraction pipeline, I will address this data quality issue by re-processing the extracted text through an LLM-based extractor with the aim of better handling the variation in section sizes and formatting. The LLM should be better at the fuzzy matching that regex has struggled with.
Analysis of Word Counts in Grants Dataframe
#check word counts for text columns in grants df
grants_text_cols = ["grant_title", "grant_desc", "recipient_activities"]
#create columns
for col in grants_text_cols:
grants_df[f"word_count_{col}"] = grants_df[col].str.split().str.len()
for col in grants_text_cols:
print(f"{col.upper()}")
print(f"{'_'*30}\n")
word_count_col = f"word_count_{col}"
not_nas = grants_df[grants_df[word_count_col].notna()]
#get minimums and maximums for each text column
if len(not_nas) > 0:
min_idx = not_nas[word_count_col].idxmin()
max_idx = not_nas[word_count_col].idxmax()
examples = grants_df.loc[[min_idx, max_idx], ["funder_num", "funder_name", "grant_id", "recipient_name", word_count_col, col]]
examples.index = ["Minimum", "Maximum"]
display(examples)
else:
print("No data available\n")GRANT_TITLE
______________________________
| funder_num | funder_name | grant_id | recipient_name | word_count_grant_title | grant_title | |
|---|---|---|---|---|---|---|
| Minimum | 1125537 | PEOPLE'S HEALTH TRUST | 360G-PeoplesHealthTrust-2015_153 | BEAT ROUTES | 1.00 | #LEVELS |
| Maximum | 263207 | JOHN ELLERMAN FOUNDATION | 360G-Ellerman-18741 | MORE IN COMMON | 38.00 | MORE IN COMMON WILL PROVIDE SUPPORT FOR THE FO... |
GRANT_DESC
______________________________
| funder_num | funder_name | grant_id | recipient_name | word_count_grant_desc | grant_desc | |
|---|---|---|---|---|---|---|
| Minimum | 263207 | JOHN ELLERMAN FOUNDATION | 360G-Ellerman-17024 | CLORE SOCIAL LEADERSHIP PROGRAMME | 1.00 | BURSARIES |
| Maximum | 1091263 | LONDON COMMUNITY FOUNDATION | 360G-LondonCF-A583241 | ACLE EVENING WOMEN'S INSTITUTE | 259.00 | MAJORITY OF OUR SERVICE USERS ARE FROM BME COM... |
RECIPIENT_ACTIVITIES
______________________________
| funder_num | funder_name | grant_id | recipient_name | word_count_recipient_activities | recipient_activities | |
|---|---|---|---|---|---|---|
| Minimum | 283813 | LONDON MARATHON CHARITABLE TRUST LIMITED | 360G-LMCT-68_2023 | EDMONTON COMMUNITY PARTNERSHIP | 1.00 | . |
| Maximum | 1091263 | LONDON COMMUNITY FOUNDATION | 360G-LondonCF-A561932 | LEWISHAM MULTILINGUAL ADVICE SERVICE | 500.00 | LEWISHAM MULTILINGUAL ADVICE SERVICE (LMLAS) I... |
#low word counts - count and view short grant details from 360Giving API/CC public extract
grant_details = {
"grant_title": "Short grant title",
"grant_desc": "Short grant description",
"recipient_activities": "Short recipient activities"
}
for col, title in grant_details.items():
grants_df[f"short_{col}_section"] = (
(grants_df[col].str.split().str.len() < 3)
)
short_grant_details = grants_df[grants_df[f"short_{col}_section"]][col].dropna().unique()
# print(f"\n{title}: {grants_df[f'short_{col}_section'].sum():,}")
# print_in_rows(short_grant_details, 12)#high word counts - check top 10 longest grant details (to manually check)
long_grant_title = get_longest_values(grants_df, "word_count_grant_title", "grant_id")
long_grant_desc = get_longest_values(grants_df, "word_count_grant_desc", "grant_id")
long_recip_activities = get_longest_values(grants_df, "word_count_recipient_activities", "grant_id")
sections = [
("grant_title", long_grant_title),
("grant_desc", long_grant_desc),
("recipient_activities", long_recip_activities)
]
for name, longest in sections:
print(f"Top 10 longest {name}: {longest}")Top 10 longest grant_title: ['360G-Ellerman-18741', '360G-Ellerman-18295', '360G-Ellerman-17745', '360G-Ellerman-18026', '360G-LMCT-07_2021', '360G-Ellerman-20290', '360G-Ellerman-20116', '360G-Ellerman-19350', '360G-Ellerman-18035', '360G-LMCT-18_2015']
Top 10 longest grant_desc: ['360G-LondonCF-A583241', '360G-PeoplesHealthTrust-2023_137', '360G-PeoplesHealthTrust-2023_39', '360G-PeoplesHealthTrust-2023_24', '360G-PeoplesHealthTrust-2014_176', '360G-PeoplesHealthTrust-2016_200', '360G-PeoplesHealthTrust-2023_25', '360G-PeoplesHealthTrust-2023_14', '360G-PeoplesHealthTrust-2014_192', '360G-PeoplesHealthTrust-2013_41']
Top 10 longest recipient_activities: ['360G-LondonCF-A584528', '360G-LondonCF-A561932', '360G-LondonCF-A584264', '360G-LondonCF-A575782', '360G-LondonCF-A566462', '360G-LondonCF-A585091', '360G-LondonCF-A583159', '360G-LondonCF-A567136', '360G-LondonCF-A561466', '360G-LondonCF-A565064']Exploration of Findings from Word Count Analysis (Grants)
The word count analysis on the grants dataframe shows that there are almost 2,000 entries with a length of fewer than three words. Having inspected these, I can see that there are a small number of unusual values that need to be cleaned, such as an entry in recipient_activities that reads #NAME?. There are also several hundred grant titles that appear to be IDs as opposed to descriptive titles (e.g. VFTF R6-SOLACE-2024); these will not lend themselves to embedding, so I will remove them. They all appear to end in a dash and a year, so can be identified by “-2”.
In terms of high word counts, there are no concerns. As with the information called from the API in the funders dataframe, the longest grant details are simply relatively long and wordy. I am confident that the information from the 360Giving API is highly reliable, with a very small minority of unexpected values that can be cleaned easily.
3. Quality of Data from APIs
Although the data that has been returned from the APIs is generally clean and reliable, there are some minor issues that require tidying.
Problems Identified by Word Count Analyses
#replace ID grant titles with None
grants_df.loc[grants_df["grant_title"].str.contains("-2", na=False), "grant_title"] = None#replace unusual values with None
unusual_values = ["#NAME?", "NIL ACTIVITY.", ".", "AS BEFORE", "IN LIQUIDATION", "NONE", "0", "N/A", "-"]
grants_df["grant_desc"] = grants_df["grant_desc"].replace(unusual_values, None)
grants_df["recipient_activities"] = grants_df["recipient_activities"].replace(unusual_values, None)#remove html entities from activities
grants_df["recipient_activities"] = grants_df["recipient_activities"].str.replace("^", "", regex=True, case=False)#clean start of activities strings
grants_df["recipient_activities"] = grants_df["recipient_activities"].str.replace("^[^a-zA-Z0-9]+", "", regex=True)#print grant details again to confirm cleaning has been successful
grant_details = {
"grant_title": "Short grant title",
"grant_desc": "Short grant description",
"recipient_activities": "Short recipient activities"
}
for col, title in grant_details.items():
grants_df[f"short_{col}_section"] = (
(grants_df[col].str.split().str.len() < 3)
)
short_grant_details = grants_df[grants_df[f"short_{col}_section"]][col].dropna().unique()
# print(f"\n{title}: {grants_df[f'short_{col}_section'].sum():,}")
# print_in_rows(short_grant_details, 12)Checking and Cleaning Other Variables (Funders)
#check funder names
name_lengths = funders_df["name"].str.len()
print(f"Funders with names < 10 characters: {(name_lengths < 10).sum()}")
print(f"Funders with names > 75 characters: {(name_lengths > 75).sum()}")
print("\nTop 10 shortest funder names (< 10 characters)")
short_names = funders_df[name_lengths < 10][["registered_num", "name", "website"]].sort_values("name", key=lambda x: x.str.len()).head(10)
display(short_names)
print("\nTop 10 longest funder names (> 75 characters)")
long_names = funders_df[name_lengths > 100][["registered_num", "name", "website"]].sort_values("name", key=lambda x: x.str.len(), ascending=False)
display(long_names)Funders with names < 10 characters: 23
Funders with names > 75 characters: 1
Top 10 shortest funder names (< 10 characters)| registered_num | name | website | |
|---|---|---|---|
| 156 | 1160614 | STAR | https://www.starfoundation.org.uk |
| 416 | 1161405 | SEDCU | https://www.sedcu.org.uk |
| 559 | 1187731 | JOSHA | None |
| 764 | 1082476 | PRAGYA | https://www.pragya.org |
| 736 | 1172017 | CLYMER | None |
| 578 | 1197149 | RESEED | https://reseed.org.uk |
| 517 | 1087870 | CMZ LTD | None |
| 783 | 1147360 | LIFT UK | https://www.liftuk.org |
| 609 | 1190525 | RHIZA UK | https://rhizauk.uk/ |
| 897 | 1041449 | MIRACLES | https://www.miraclesthecharity.org |
Top 10 longest funder names (> 75 characters)| registered_num | name | website | |
|---|---|---|---|
| 904 | 220487 | CHARITY FOR THE REPARATION OF THE CHURCH AND S... | None |
#check funder websites
website_lengths = funders_df["website"].str.len()
print(f"Funders with websites < 15 characters: {(website_lengths < 15).sum()}")
print(f"Funders with websites > 75 characters: {(website_lengths > 75).sum()}")
print("\nTop 10 shortest funder websites (< 15 characters)")
short_websites = funders_df[website_lengths < 15][["registered_num", "name", "website"]].sort_values("website", key=lambda x: x.str.len()).head(10)
display(short_websites)
print("\nTop 10 longest funder websites (> 75 characters)")
long_websites = funders_df[website_lengths > 75][["registered_num", "name", "website"]].sort_values("website", key=lambda x: x.str.len(), ascending=False)
display(long_websites)Funders with websites < 15 characters: 6
Funders with websites > 75 characters: 2
Top 10 shortest funder websites (< 15 characters)| registered_num | name | website | |
|---|---|---|---|
| 839 | 801622 | SUSAN AND STEPHEN JAMES CHARITABLE SETTLEMENT | |
| 616 | 1126336 | ANAV CHARITABLE TRUST | |
| 767 | 1069996 | SUPPORT TIFFIN GIRLS' SCHOOL COMPANY | |
| 266 | 246116 | CLERGY WIDOWS' AND ORPHANS' FUND | |
| 272 | 1138049 | PERU PEOPLE | |
| 159 | 287404 | LIBRARY SERVICES TRUST | https://L.S.T |
Top 10 longest funder websites (> 75 characters)| registered_num | name | website | |
|---|---|---|---|
| 955 | 200693 | EVERSHOLT PAROCHIAL CHARITY | https://www.eversholtvillage.co.uk/history-fac... |
| 51 | 273057 | WYMONDHAM COLLEGE PARENT-STAFF ASSOCIATION | https://www.wymondhamcollege.org/home/partners... |
#reassign null to incorrectly stored urls
funders_df.loc[website_lengths < 15, "website"] = None#remove leading characters from paragraph columns
funders_df["activities"] = funders_df["activities"].apply(clean_start_of_text)
funders_df["objectives"] = funders_df["objectives"].apply(clean_start_of_text)Checking and Cleaning Other Variables (Grants)
#check recipient ids - view ids with unexpected starting characters
invalid_ids = grants_df[~grants_df["recipient_id"].str.startswith(("1", "2", "3", "4", "5", "6", "7", "8", "9", "P"), na=False)]["recipient_id"].unique()
# print(list(invalid_ids))#store original ids
grants_df["original_recipient_id"] = grants_df["recipient_id"].copy()
#remove incorrect spaces and 0s
grants_df["recipient_id"] = grants_df["recipient_id"].astype(str).str.strip()
grants_df["recipient_id"] = grants_df["recipient_id"].str.lstrip("0")
#reassign remaining invalid ids
invalid_ids = ~grants_df["recipient_id"].str.startswith(("1", "2", "3", "4", "5", "6", "7", "8", "9", "P"), na=False)
grants_df.loc[invalid_ids, "recipient_id"] = [f"invalid_{i}" for i in range(invalid_ids.sum())]
#map old and new ids
id_mapping = grants_df[grants_df["recipient_id"] != grants_df["original_recipient_id"]][["original_recipient_id", "recipient_id"]].drop_duplicates()
#check result
invalid_ids = grants_df[~grants_df["recipient_id"].str.startswith(("1", "2", "3", "4", "5", "6", "7", "8", "9", "P", "i"), na=False)]["recipient_id"].unique()
print(f"Invalid IDs remaining: {list(invalid_ids)}")Invalid IDs remaining: []#remove leading characters from paragraph columns
grants_df["recipient_activities"] = grants_df["recipient_activities"].apply(clean_start_of_text)Explanation of Cleaning Process
Funder Names and Websites
I am satisfied that there are no concerns with the length of funder names. Looking at the shortest websites, there appeared to be one invalid URL, and five that are stored in an incorrect null format; I reassigned all six of these to None.
Recipient IDs
Some values in recipient_id need to be cleaned. There is a small subset with incorrect starting characters, and several that are not registered charity numbers. Working with organisations that are not registered with the Charity Commission (of England & Wales) is out of the scope of this project. Where there is clearly an error in the Charity Commission registered number, I have cleaned these values. I have removed spaces and 0s from the start of IDs and reassigned any other values (e.g. N/A or Exempt) to show that the ID was invalid. Where recipient_id is a company number or a registered number from Scotland or Northern Ireland, I have also assigned an “invalid” ID. The text content of these records can be embedded as-is, but anything else (e.g. calling a different API) is out of the scope of the project so no additional value will be gleaned from keeping the original IDs.
4. Quality of Extracted Sections and Grants
Sections
To extract sections (i.e activities_objectives, achievements_performance and grants_policy), I have relied on regex matching. Unfortunately, as observed during the Word Count Analysis, there are noteable errors and quality issues that would degrade the quality of embeddings and undermind the reliability of semantic similarity comparisons. As such, they cannot be ignored. The grants have been extracted using the Claude API (using the Haiku 3 model), which has resulted in some errors but not to the same extent, and not as irreperable. I will reprocess the PDFs by running them through the Claude API, to improve the chances of the sections being correctly and consistently extracted.
#load reprocessed sections
sections_df = pd.read_csv("./6.2_sections_reprocessor/llm_sections.csv")
sections_df.head()| registered_num | year_processed | objectives_activities | achievements_performance | grant_policy | error | |
|---|---|---|---|---|---|---|
| 0 | 272161 | 2024 | The trustees are directed by the trust deed to... | The Trust generated £261,918 (2023: £259,731) ... | The published policy of the trustees is to hel... | NaN |
| 1 | 211715 | 2024 | The object of the Trust is to relieve persons ... | During the year the Grants Sub-Committee revie... | The Trustees consider applications for grants ... | NaN |
| 2 | 1007307 | 2024 | The objective of the charity is to provide fin... | NaN | NaN | NaN |
| 3 | 235891 | 2024 | The charity is controlled by its governing doc... | NaN | NaN | NaN |
| 4 | 803686 | 2025 | The charity is a non-profit seeking charitable... | The charity's achievements during the period i... | When considering applications for grants, the ... | NaN |
#check efficacy of sections reprocessor
sections_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 295 entries, 0 to 294
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 registered_num 295 non-null int64
1 year_processed 295 non-null int64
2 objectives_activities 276 non-null object
3 achievements_performance 263 non-null object
4 grant_policy 154 non-null object
5 error 5 non-null object
dtypes: int64(2), object(4)
memory usage: 14.0+ KB#view 10% random selection of each reprocessed section
section_columns = ["objectives_activities", "achievements_performance", "grant_policy"]
for col in section_columns:
#get sample of sections with values
non_null = sections_df[sections_df[col].notna()]
sample_size = int(len(non_null) * 0.1)
sample = non_null.sample(n=sample_size, random_state=42)
#display sections to spotcheck
print(f"\n{col.upper()}")
print(f"Total: {len(non_null)}\nSample: {sample_size}\n")
# for idx, (i, row) in enumerate(sample.iterrows(), 1):
# print(f"---Sample {idx} (Funder {row['registered_num']})---")
# print(row[col])
# print()
OBJECTIVES_ACTIVITIES
Total: 276
Sample: 27
ACHIEVEMENTS_PERFORMANCE
Total: 263
Sample: 26
GRANT_POLICY
Total: 154
Sample: 15
#drop sections columns from funder df
sections_cols = ["objectives_activities", "achievements_performance", "grant_policy"]
funders_df = funders_df.drop(columns=sections_cols, errors="ignore")
sections_df["registered_num"] = sections_df["registered_num"].astype(str)
#make sections uppercase
for col in sections_cols:
sections_df[col] = sections_df[col].str.upper()
#merge reprocessed sections back into funders df
funders_df = funders_df.merge(
sections_df[["registered_num"] + sections_cols],
on="registered_num",
how="left"
)
#confirm merge
print(f"objectives_activities: {funders_df['objectives_activities'].notna().sum()}, \
achievements_performance: {funders_df['achievements_performance'].notna().sum()}, \
grant_policy: {funders_df['grant_policy'].notna().sum()}")objectives_activities: 276, achievements_performance: 263, grant_policy: 154Exploration of Reprocessed Sections
The output from the .info() method shows that more funders now have values for the extracted sections - increasing from 52 to 154 funders with grant_policy, from 193 to 263 funders with achievements_peformance and from 229 to 276 funders with objectives_activities. The random spotcheck of 10% of the values for each section has revealed that the quality is much higher. Other than some small spelling errors (e.g. Uttar Grades instead of Uttar Pradesh), there do not seem to be extensive quality issues in these sections that could severely impact the quality of embeddings. The fact that I have noted issues with extracted grants (which have only ever been extracted using Claude) demonstrates that using an LLM to extract text from PDFs cannot be relied upon as a perfect method; however, given its substantial improvement over regex matching (and the absence of more robust extraction methods within the project’s constraints), I consider it to be the most appropriate solution available.
Grants - Names
The messiest part of the extracted grants data is recipient_name, which has been built from two sources. The first is the Charity Commission’s Public Extract, which is updated daily and includes registered charities’ names as logged with the Charity Commission. These names are generally clean and standardised, though charities occasionally use trading names that differ from their official registered names.
The second source is the organisation’s name as extracted from funders’ accounts by the Claude API. This is significantly less reliable and is a noted limitation of this project. The reliability is affected in part by the reliance on a large language model and its fuzzy intepretations of messy text (although this is clearly preferable to regex), but also due to the fact that funders’ accounts are not held to any standard of enforcement in terms of the correct spelling, uniformity, or indeed accuracy of recipients’ names. Examples that have been noted during the course of this project include inconsistency in pluralisation and spacing (e.g. hospices vs hospice, Tearfund vs Tear Fund); missing words (e.g. British Red Cross Society vs British Red Cross); errors in punctuation (e.g. soldiers’ vs solider’s); and inconsistency in word order (e.g. Lincoln University vs University of Lincoln). These inconsistencies mean that grants to the same recipient may appear under multiple name variants in the database. However, as the current system focuses on funder-applicant alignment rather than recipient-level analysis these naming inconsistencies will not impact the core functionality and this remains an area for future development.
Human Recipients of Grants
As some funders give grants to individuals as well as organisations, Claude API has extracted some human names from the accounts. This is publicly available data but, even so, I do not feel comfortable storing people’s names in my database - plus, it will add no value to the project. As such, I will attempt to flag the human records for removal.
#flag records that might be human names
extracted_recipients = grants_df[grants_df["recipient_id"].str.startswith("PDF", na=False)].copy()
extracted_recipients["is_potential_human"] = extracted_recipients["recipient_name"].apply(check_names)
flagged_as_human = extracted_recipients[extracted_recipients["is_potential_human"]]["recipient_name"].unique()
print(f"Total unique extracted recipients: {extracted_recipients['recipient_name'].nunique():,}")
print(f"Names flagged as potentially human: {len(flagged_as_human):,}")
#add as column to grants_df
grants_df["is_potential_human"] = False
grants_df.loc[grants_df["recipient_id"].str.startswith("PDF", na=False), "is_potential_human"] = \
grants_df.loc[grants_df["recipient_id"].str.startswith("PDF", na=False), "recipient_name"].apply(check_names)Total unique extracted recipients: 6,865
Names flagged as potentially human: 552grants_df.sort_values("is_potential_human", ascending=False).head(2)| grant_title | grant_desc | amount | year | grant_id | source | funder_num | funder_grants_id | funder_name | recipient_id | recipient_grants_id | recipient_name | recipient_activities | recipient_areas | recipient_causes | recipient_beneficiaries | amount_gbp | word_count_grant_title | word_count_grant_desc | word_count_recipient_activities | short_grant_title_section | short_grant_desc_section | short_recipient_activities_section | original_recipient_id | is_potential_human | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 20615 | None | None | 1218.04 | 2023 | 2023_226743_24 | Accounts | 226743 | 59728 | KNARESBOROUGH RELIEF IN NEED CHARITY | PDF-000185 | 58539 | AMANDA AGNEW | None | [] | [] | [] | £1,218.04 | NaN | NaN | NaN | False | False | False | PDF-000185 | True |
| 20619 | None | None | 921.50 | 2023 | 2023_226743_28 | Accounts | 226743 | 59732 | KNARESBOROUGH RELIEF IN NEED CHARITY | PDF-000189 | 58543 | LAURA ANDERSON | None | [] | [] | [] | £921.50 | NaN | NaN | NaN | False | False | False | PDF-000189 | True |
#remove records
grants_df = grants_df[~((grants_df["funder_name"] == "KNARESBOROUGH RELIEF IN NEED CHARITY") &
(grants_df["is_potential_human"] == True))]#delete rows where recipient_name starts with a number
grants_df = grants_df[~grants_df["recipient_name"].str.match(r'^\d', na=False)]Grants - Duplication
Charity accounts follow a comparative reporting format where they present figures for both the current financial year and the previous financial year side by side. This means that the grants that have been extracted by the LLM are likely to be duplicated in some cases. I will identify duplicates by comparing the funder, recipient, grant amount and years. Where the exact same funder-recipient-amount combination is found in two consecutive years this is likely to be a duplicate, so I will remove these instances.
#sort grants extracted from accounts to spot duplicates
accounts_grants = grants_df[grants_df["source"] == "Accounts"].copy()
accounts_grants = accounts_grants.sort_values(["funder_num", "recipient_name", "amount", "year"])
#compare via shifted column
accounts_grants["prev_funder"] = accounts_grants["funder_num"].shift(1)
accounts_grants["prev_recipient"] = accounts_grants["recipient_name"].shift(1)
accounts_grants["prev_amount"] = accounts_grants["amount"].shift(1)
accounts_grants["prev_year"] = accounts_grants["year"].shift(1)
#mark as duplicate is same funder, recipient and amount but one year apart
accounts_grants["is_consecutive_dup"] = (
(accounts_grants["funder_num"] == accounts_grants["prev_funder"]) &
(accounts_grants["recipient_name"] == accounts_grants["prev_recipient"]) &
(accounts_grants["amount"] == accounts_grants["prev_amount"]) &
((accounts_grants["year"] - accounts_grants["prev_year"]) == 1)
)
print(f"Found {accounts_grants['is_consecutive_dup'].sum()} consecutive year duplicates")Found 1820 consecutive year duplicates#remove duplicated grants and combine back with other grants
accounts_deduped = accounts_grants[~accounts_grants["is_consecutive_dup"]].drop(
columns=["prev_funder", "prev_recipient", "prev_amount", "prev_year", "is_consecutive_dup"]
)
g360_grants = grants_df[grants_df["source"] == "360Giving"]
grants_df = pd.concat([g360_grants, accounts_deduped], ignore_index=True)
print(f"Removed {len(accounts_grants) - len(accounts_deduped)} duplicate grants")
print(f"New total grants: {len(grants_df):,}")Removed 1820 duplicate grants
New total grants: 30,955Grants - Amounts
As explored during the missingness analysis, some amounts are null and I have chosen to retain these. I will also sense check very small and very large amounts to confirm that they are indeed correct. I will exclude grants with values of £0 because these are typically accounting adjustments, regranted funds, or administrative entries rather than nulls or actual grant awards (360Giving, n.d.).
#get grants less than £100 except where this is expected
low_value_grants = grants_df[(grants_df["amount"] < 100) & (grants_df["amount"] > 0) & \
(~grants_df["funder_name"].str.startswith("ROTARY", na=False)) & \
(~grants_df["funder_name"].str.startswith("JAMES", na=False))]#multiply by 1000 where relevant
multiply_000s_funders = ["1060133", "255281"]
for fun_num in multiply_000s_funders:
grants_df.loc[(grants_df["funder_num"] == fun_num) & (grants_df["amount"] < 100), "amount"] = \
grants_df.loc[(grants_df["funder_num"] == fun_num) & (grants_df["amount"] < 100), "amount"] * 1000
#reassign where amount is incorrect
grants_df.loc[(grants_df["funder_num"] == "298083") & (grants_df["amount"] == 1), "amount"] = None
grants_df.loc[(grants_df["grant_id"] == "2023_1045479_1"), "amount"] = 278.00
#recalculate gbp amounts
grants_df["amount_gbp"] = grants_df["amount"].apply(add_gbp_columns)
#drop rows with human names
grants_df = grants_df[(grants_df["recipient_id"] != "PDF-000179") & (grants_df["recipient_id"] != "PDF-000180")]low_value_cleaned = grants_df[(grants_df["amount"] < 100) & (grants_df["amount"] > 0) & \
(~grants_df["funder_name"].str.startswith("ROTARY", na=False)) & \
(~grants_df["funder_name"].str.startswith("JAMES", na=False))]
low_value_cleaned.head(5)| grant_title | grant_desc | amount | year | grant_id | source | funder_num | funder_grants_id | funder_name | recipient_id | recipient_grants_id | recipient_name | recipient_activities | recipient_areas | recipient_causes | recipient_beneficiaries | amount_gbp | word_count_grant_title | word_count_grant_desc | word_count_recipient_activities | short_grant_title_section | short_grant_desc_section | short_recipient_activities_section | original_recipient_id | is_potential_human | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 18912 | None | None | 14.00 | 2021 | 2021_1045479_1 | Accounts | 1045479 | 64186 | BARKER-MILL FOUNDATION | PDF-002489 | 62997 | PAROCHIAL CHURCH COUNCIL OF THE ECCLESIASTICAL... | None | [] | [] | [] | £14.00 | NaN | NaN | NaN | False | False | False | PDF-002489 | False |
| 22513 | None | None | 30.00 | 2020 | 2020_222652_14 | Accounts | 222652 | 62270 | ROCHDALE FUND FOR RELIEF IN SICKNESS | PDF-001568 | 61081 | INJURED JOCKEY'S FUND | None | [] | [] | [] | £30.00 | NaN | NaN | NaN | False | False | False | PDF-001568 | False |
| 22635 | None | None | 51.00 | 2021 | 2021_223903_18 | Accounts | 223903 | 62780 | CLEEVES AND WHITEHEAD TRUST | PDF-001805 | 61591 | CARL WHITEHEAD LODGE | None | [] | [] | [] | £51.00 | NaN | NaN | NaN | False | False | False | PDF-001805 | False |
| 22842 | None | None | 25.00 | 2021 | 2021_224590_1 | Accounts | 224590 | 62504 | SHAW LANDS TRUST | PDF-001638 | 61315 | BARNSLEY & DISTRICT GENERAL HOSPITAL | None | [] | [] | [] | £25.00 | NaN | NaN | NaN | False | False | False | PDF-001638 | False |
| 22843 | None | None | 35.00 | 2020 | 2020_224590_1 | Accounts | 224590 | 62544 | SHAW LANDS TRUST | PDF-001638 | 61355 | BARNSLEY & DISTRICT GENERAL HOSPITAL | None | [] | [] | [] | £35.00 | NaN | NaN | NaN | False | False | False | PDF-001638 | False |
Explanation of Grants Cleaning Process
There are 6,865 grants in the database that have been extracted from PDFs, but using the names dataset I was able to filter this to 552 flagged as potentially containing human names. I could immediately see that the main culprit was a funder called KNARESBOROUGH RELIEF IN NEED CHARITY, which has named its individual recipients in its accounts. For the sake of reproducibility, I will programmatically remove records from this funder and with only two words - but for a more thorough removal it would be best to inspect each PDF-extracted grant record manually.
The deduplication process keeps the earliest year of each grant, as the earlier accounts show the actual grant, and later accounts are just showing “prior year” comparisons. In terms of functionality, this means that prospie will be able to inform the user, for example, ‘this funder gave £1,000 to XYZ Charity in 2023’.
Regarding cleaning the grants amounts data, I checked for values lower than £100 as this is a relatively unusual value for a grant. This showed that some funders (such as Rotary Clubs) can be expected to give low value grants, as this is how their distribution model works. Around 60% of the remaining low value were attributable to grants being reported in thousands of pounds (£000s) in the original accounts, e.g. a grant of £22,000 was recorded as £22, so I multiplied these values by 1000. The last transformation on grant amounts was for one funder whose accounts included the names of grant recipients but not values, and the LLM had mistakenly assigned an incorrect value of £1 to these grants. A spotcheck of the remaining low value suggests that these are accurate, with 0.14% of the grants in the dataset having a value of less than £100.
Descriptive Statistics
Summary Statistics
#build df of summary statistics
summary_data = make_summary_df(funders_df, grants_df)
summary_df = pd.DataFrame(summary_data)
summary_df["Value"] = summary_df.apply(format_stats, axis=1)
summary_df = format_df(summary_df)| Metric | Value |
|---|---|
| Total funders | 996 |
| Funders with grants | 309 |
| Funders with grants from 360Giving | 11 |
| Total recipients | 19,466 |
| Total grants | 30,716 |
| Total grant value | £1,428,662,939.67 |
| Mean grants per funder | 106 |
| Most grants given by a funder | 6,987 |
| Fewest grants given by a funder | 1 |
| Mean recipients per funder | 72.9 |
| Mean areas per funder | 3.6 |
| Mean funder income | £1,258,942.79 |
| Median funder income | £46,068.00 |
| Mean funder expenditure | £1,188,764.68 |
| Median funder expenditure | £43,765.50 |
| Largest funder by mean income | Save The Children Fund (£284,868,800.00) |
| Largest funder by mean expenditure | Save The Children Fund (£281,939,194.60) |
| Mean grants per recipient | 1.6 |
| Range of grants received | 1 to 79 |
| Recipient of largest grant | Patricia, Donald, Christine & Patrick Shepherd Foundation (£11,182,253.00) From Patricia And Donald Shepherd Charitable Trust |
| Mean grant size | £46,587.85 |
| Median grant size | £11,791.50 |
| Standard deviation | £148,858.47 |
| Smallest grant | £14.00 |
| Largest grant | £11,182,253.00 |
| Earliest grant | 2001 |
Calculated Statistics
#get calculated stats and build df
stats = calculate_stats(funders_df, grants_df)
calculated_data = make_calculated_df(stats)
calculated_df = pd.DataFrame(calculated_data)
calculated_df["Value"] = calculated_df.apply(format_stats, axis=1)
calculated_df = format_df(calculated_df)| Metric | Value |
|---|---|
| Share of grants from top 10% funders (by income) | 71.6% |
| Share of grants to top 10% recipients (by grant value) | 71.5% |
| Percent of recipients with multiple grants from same funder | 21.5% |
| Average grants per funder-recipient pair | 1 |
| Mean grants-to-income ratio | 119.6% |
| Median grants-to-income ratio | 57.6% |
| Percent of funders supporting General Charitable Purposes only | 16.8% |
| Percent of extracted grants matched with recipient data | 23.2% |
Exploration of Giving Patterns and Funder Characteristics
1. Categorical Analysis
Classification Popularity
One of the key objectives of prospie is to help fundraisers navigate the confusing trusts landscape, which is confusing largely due to the mismatch of information that is available. Funders may indicate a particular cause or area of activity, but these do not always align with their actual giving habits. I will therefore compare the classifications that funders state (their identified causes, beneficiaries, and areas of activity) with those of the recipients who are awarded their grants.
#display plots to compare funders' and recipients' classifications
fig, axes = plt.subplots(3, 2, figsize=(18, 15))
#areas
make_bar_chart(grants_df, "recipient_areas", "Recipients: Most Popular Areas", color=colours[1], ax=axes[1, 0])
make_bar_chart(funders_df, "areas", "Funders: Most Popular Areas", color=colours[1], ax=axes[1, 1])
#beneficiaries
make_bar_chart(grants_df, "recipient_beneficiaries", "Recipients: Most Popular Beneficiaries", color=colours[2], ax=axes[2, 0])
make_bar_chart(funders_df, "beneficiaries", "Funders: Most Popular Beneficiaries", color=colours[2], ax=axes[2, 1])
#causes
make_bar_chart(grants_df, "recipient_causes", "Recipients: Most Popular Causes", color=colours[0], ax=axes[0, 0])
make_bar_chart(funders_df, "causes", "Funders: Most Popular Causes", color=colours[0], ax=axes[0, 1])
plt.tight_layout()
plt.subplots_adjust(hspace=0.4)
plt.show()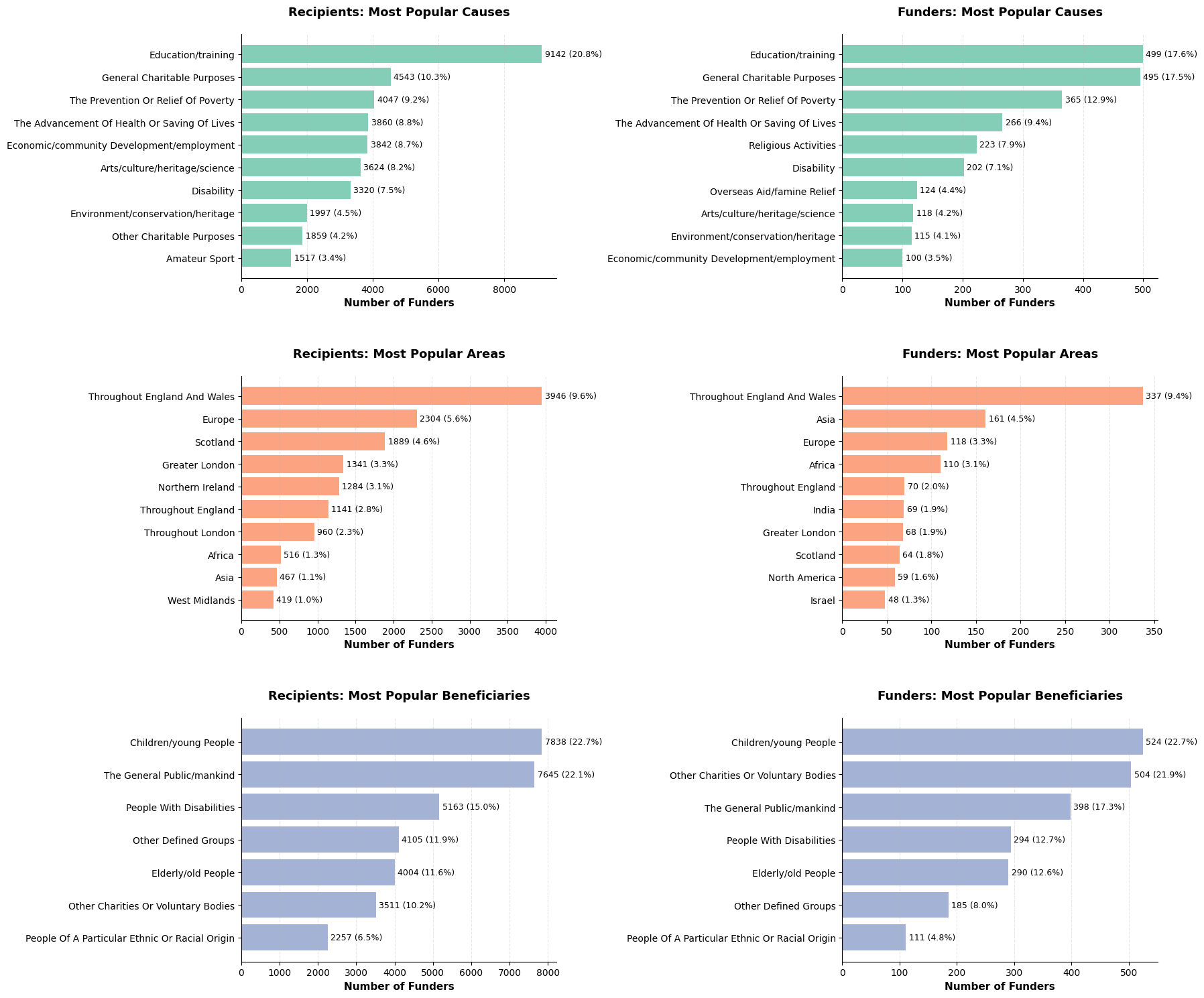
Relationships between Categories
#explode classification columns
exploded_classifications = grants_df[["recipient_causes", "recipient_beneficiaries"]].copy()
exploded_classifications = exploded_classifications.explode("recipient_causes").explode("recipient_beneficiaries")
exploded_classifications = exploded_classifications.dropna()
#create crosstab
crosstab = pd.crosstab(exploded_classifications["recipient_causes"], exploded_classifications["recipient_beneficiaries"])
#create heatmap
plt.figure(figsize=(12, 8))
sns.heatmap(crosstab, cmap="Oranges", cbar_kws={"label": "Number of Grants"})
plt.title("Causes vs Beneficiaries Heatmap", fontsize=14, fontweight="bold")
plt.xlabel("Beneficiaries")
plt.ylabel("Causes")
plt.xticks(rotation=45, ha="right")
plt.yticks(rotation=0)
plt.tight_layout()
plt.show()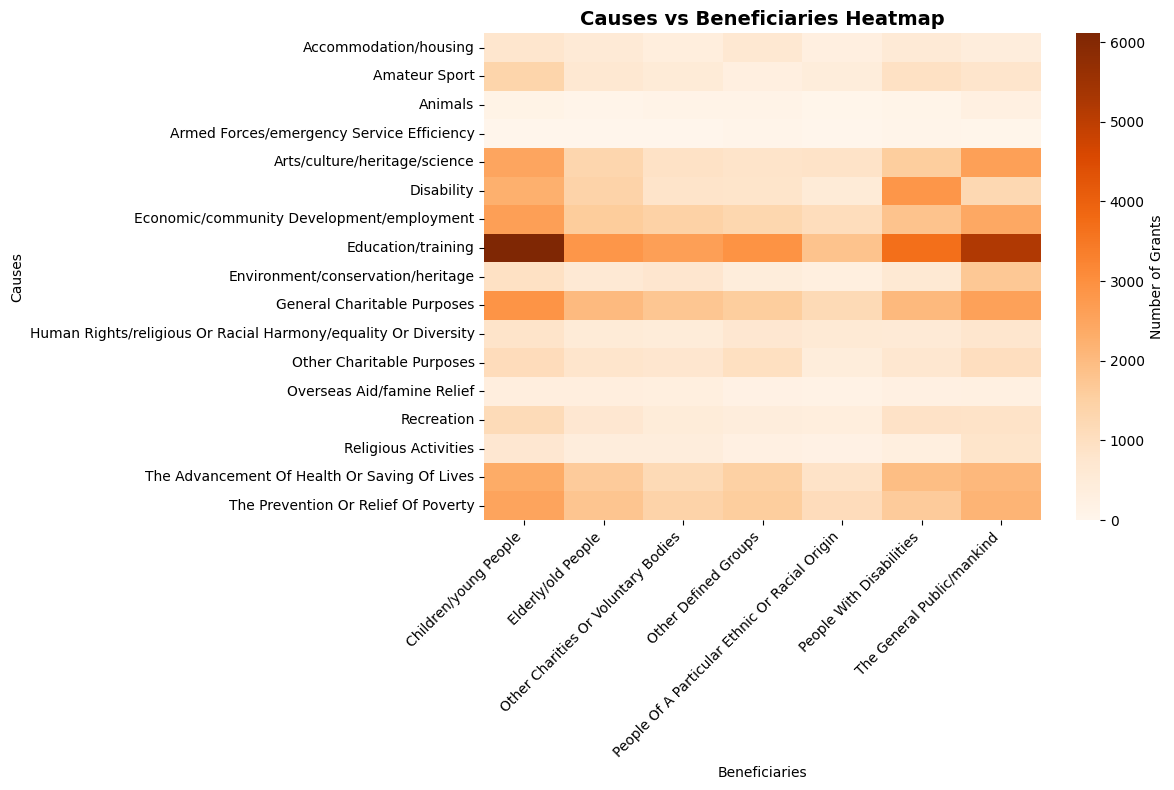
Diversity of Giving Across Categories
#count unique categories per funder
funder_diversity = grants_df.groupby("funder_num").agg({
"recipient_areas": lambda x: len(set([a for areas in x for a in areas])),
"recipient_beneficiaries": lambda x: len(set([b for bens in x for b in bens])),
"recipient_causes": lambda x: len(set([c for causes in x for c in causes]))
}).rename(columns={"recipient_areas": "unique_areas",
"recipient_beneficiaries": "unique_beneficiaries",
"recipient_causes": "unique_causes",})
#create histograms
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
categories = [
("unique_areas", "Areas", colours[1]),
("unique_beneficiaries", "Beneficiaries", colours[2]),
("unique_causes", "Causes", colours[0])
]
for idx, (col, label, colour) in enumerate(categories):
#remove recipients with missing classifications
diversity_filtered = funder_diversity[funder_diversity[col] > 0]
if col == "unique_areas":
axes[idx].hist(diversity_filtered[col], bins=20, color=colour)
else:
value_counts = diversity_filtered[col].value_counts().sort_index()
axes[idx].bar(value_counts.index, value_counts.values, color=colour)
axes[idx].xaxis.set_major_locator(plt.MaxNLocator(integer=True))
axes[idx].set_title(f"Diversity of Giving - {label}")
axes[idx].set_xlabel(f"Number of Unique {label} Funded")
axes[idx].set_ylabel("Number of Funders")
axes[idx].grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.show()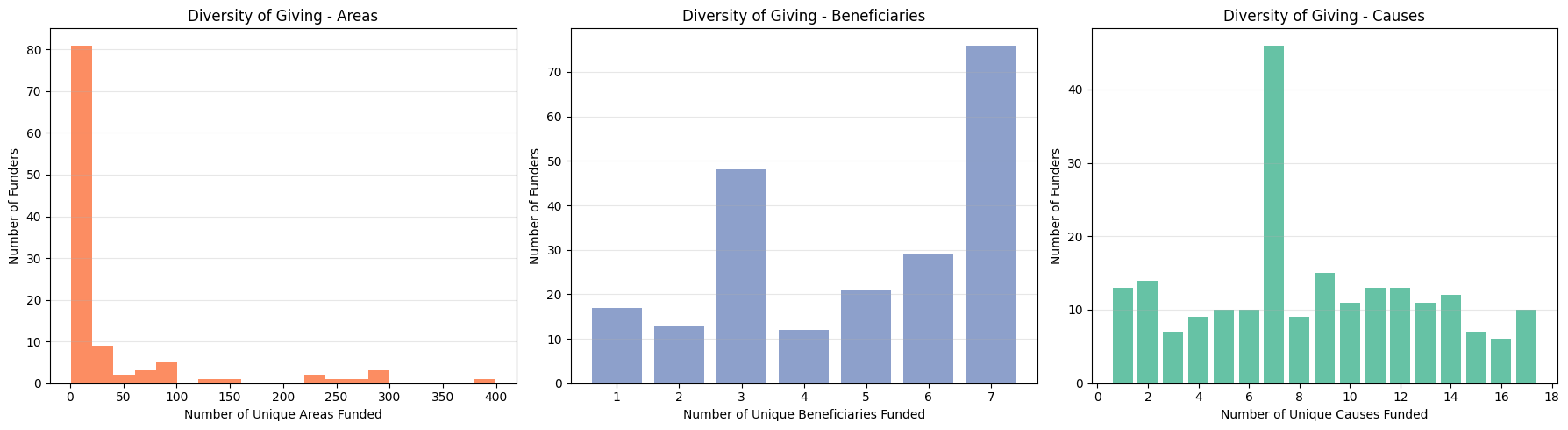
Categorical Match Rates
#add funder classifications to grants_df
grants_funders_merge = grants_df.merge(
funders_df[["registered_num", "causes", "areas", "beneficiaries"]],
left_on="funder_num",
right_on="registered_num",
how="left",
suffixes=("", "_funder")
)
#find overlaps to identify matches (only where recipients have classifications)
for category in ["areas", "beneficiaries", "causes"]:
grants_funders_merge[f'{category}_match'] = grants_funders_merge.apply(lambda row: check_overlap(row[category], row[f'recipient_{category}']), axis=1)
with_classifications = grants_funders_merge[
(grants_funders_merge["recipient_areas"].str.len() > 0) &
(grants_funders_merge["recipient_beneficiaries"].str.len() > 0) &
(grants_funders_merge["recipient_causes"].str.len() > 0)
]
#calculate funder match rates
funder_match_rates = with_classifications.groupby("funder_num").agg({
"areas_match": ["sum", "mean"],
"beneficiaries_match": ["sum", "mean"],
"causes_match": ["sum", "mean"],
"grant_id": "count"
}).reset_index()
funder_match_rates.columns = ["funder_num", "areas_matches", "areas_match_rate", "beneficiaries_matches", "beneficiaries_match_rate", "causes_matches", "causes_match_rate",
"total_grants"]
#add names
funder_match_rates = funder_match_rates.merge(
funders_df[["registered_num", "name"]],
left_on="funder_num",
right_on="registered_num"
)
#create histograms
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
for idx, category in enumerate(["areas", "beneficiaries", "causes"]):
col = f"{category}_match_rate"
mean_val = funder_match_rates[col].mean()
axes[idx].hist(funder_match_rates[col], bins=20, color=colours[idx])
axes[idx].axvline(mean_val, color="red", linestyle="--", linewidth=2,
label=f"Mean: {mean_val:.1%}")
axes[idx].set_xlabel("Match Rate")
axes[idx].set_ylabel("Number of Funders")
axes[idx].set_title(f"{category.title()} Match Rate Distribution")
axes[idx].legend()
plt.tight_layout()
plt.show()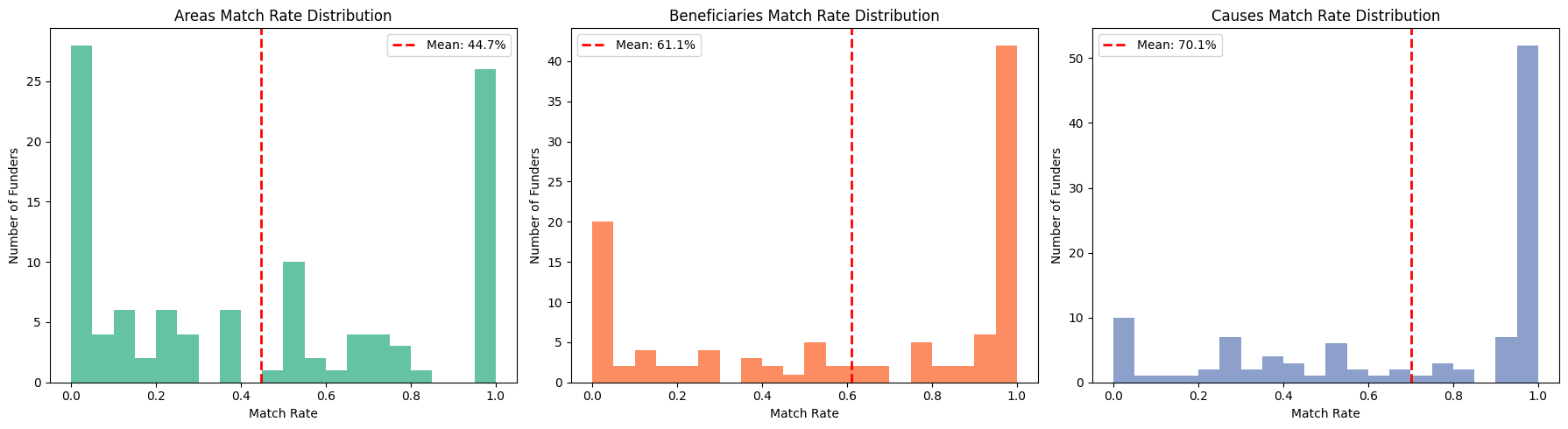
Exploration of Findings from Categorical Analysis
It can be observed that funders often state an interest in general causes, areas and beneficiaries - many do not specify particular interests and state that they will consider applications from any area of the sector. Further analysis will be useful, particularly following the creation of embeddings, to understand the practical reality of their funding priorities, which may reveal implicit preferences or local biases not reflected in their published criteria, e.g. if ‘in reality, donations are completely earmarked for a few select beneficiaries’ (Lock and Robinson, 2023).
Whilst the heatmap shows the relationship between causes and beneficiaries across all grants, it is heavily skewed by high-volume funders like Esmée Fairbairn Foundation (6,000+ grants). This means that the patterns shown reflect individual funder preferences rather than sector-wide trends, so it does not offer us much useful insight or relevance to the alignment model. It would be more useful to analyse funder behaviour on an individual level, such as quantifying how well their stated preferences match with their actual giving.
Most funders concentrate their giving within a relatively narrow scope. There’s a long tail of funders who spread their giving more widely, but these are the exception. This clustering suggests that funders typically have quite focused areas of interest, even whe they state broad ranges in their registered details. I was unable to find an explicit explanation of the huge peak at 7 causes supported, but evidence suggests that Charity Commission classifications may have previously been limited to seven general causes, before a wider range of more precise causes were implemented at a later date.
Match rates show an interesting pattern - causes has the highest match rate at around 70%, followed by beneficiaries at 61%, whilst areas sits lowest at 45%. However, this doesn’t mean causes are more important - it’s actually the opposite. Causes are often incredibly generic (many charities state that they work in vague areas such as ‘education’ or ‘health’), so high match rates don’t tell us much. Areas, on the other hand, can be specific right down to town level, so a match there is much more meaningful. This has important implications for the weighting - areas need to be weighted more highly to reflect their specificity, and keyword matching will need careful calibration to avoid over-scoring when generic terms like ‘education’ appear on both sides.
A limitation of undertaking the analysis at this stage is missing recipient data; only 23.2% of grants that have been extracted from accounts are matched with a recipient (with data added by the recipients_table_builder). This means that around 3/4 of recipients do not have classifications data to analyse. This analysis will likely be more insightful once the embeddings data is available and semantic analysis can be performed on recipient_name and funders’ details.
2. Temporal and Financial Analysis
There is a disparity in the number of grants from each data source (i.e. the 360Giving API and extracted from accounts); the API returns historical data for this sample of funders reaching back to 2001, whereas accounts downloaded from the Charity Commission website date back only five years - 2020 at the point of writing. As such, there is a notable increase in the number of grants from 2020. This is a limitation to the strength of the analysis of giving volume, but it is still possible to explore patterns in grant amounts and other factors over time.
#set up analysis dfs
grants_source_yr = grants_df.groupby(["year", "source"]).agg({
"grant_id": "count",
"amount": ["sum", "mean"]
}).reset_index()
grants_source_yr.columns = ["year", "source", "num_grants", "total_amount", "avg_amount"]
grants_yr = grants_df.groupby("year").agg({
"grant_id": "count",
"amount": ["sum", "mean", "median"]
}).reset_index()
grants_yr.columns = ["year", "num_grants", "total_amount", "avg_amount", "median_amount"]
grants_over_1 = grants_df[grants_df["amount"] > 0].copy()
years_unique = sorted(grants_over_1["year"].unique())
data_by_year = [grants_over_1[grants_over_1["year"] == year]["amount"].values for year in years_unique]Number of Grants
#pivot to look at grants by source and year
grants_pivot = grants_source_yr.pivot(index="year", columns="source", values="num_grants").fillna(0)
#create stacked bar chart
fig, ax = plt.subplots(figsize=(12, 6))
ax.stackplot(grants_pivot.index,
grants_pivot["360Giving"],
grants_pivot["Accounts"],
labels=["360Giving", "Accounts"],
colors=[colours[0], colours[1]],
alpha=0.7)
ax.set_title("Number of Grants by Source Over Time", fontsize=14, fontweight="bold")
ax.set_ylabel("Number of Grants")
ax.legend(loc="upper left")
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()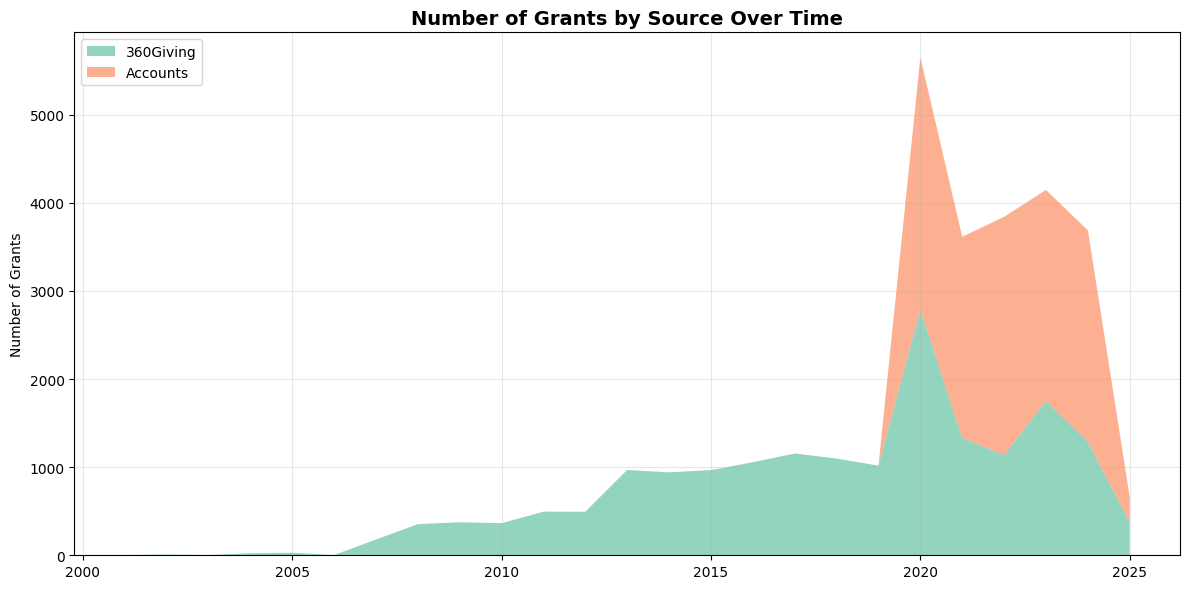
Values of Grants
#create line chart
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(grants_yr["year"], grants_yr["total_amount"], marker="o", linewidth=2, color=colours[2], label="Total")
for source in grants_source_yr["source"].unique():
data = grants_source_yr[grants_source_yr["source"] == source]
color = colours[0] if source == "360Giving" else colours[1]
ax.plot(data["year"], data["total_amount"], marker=".", linewidth=1.5, color=color, alpha=0.4, linestyle="--", label=source, zorder=2)
ax.set_title("Total Amount Awarded Over Time", fontsize=14, fontweight="bold")
ax.set_ylabel("£ (millions)")
ax.legend(loc="upper left")
ax.grid(True, alpha=0.3)
ax.yaxis.set_major_formatter(FuncFormatter(lambda x, p: f'{x/1_000_000}'))
plt.tight_layout()
plt.show()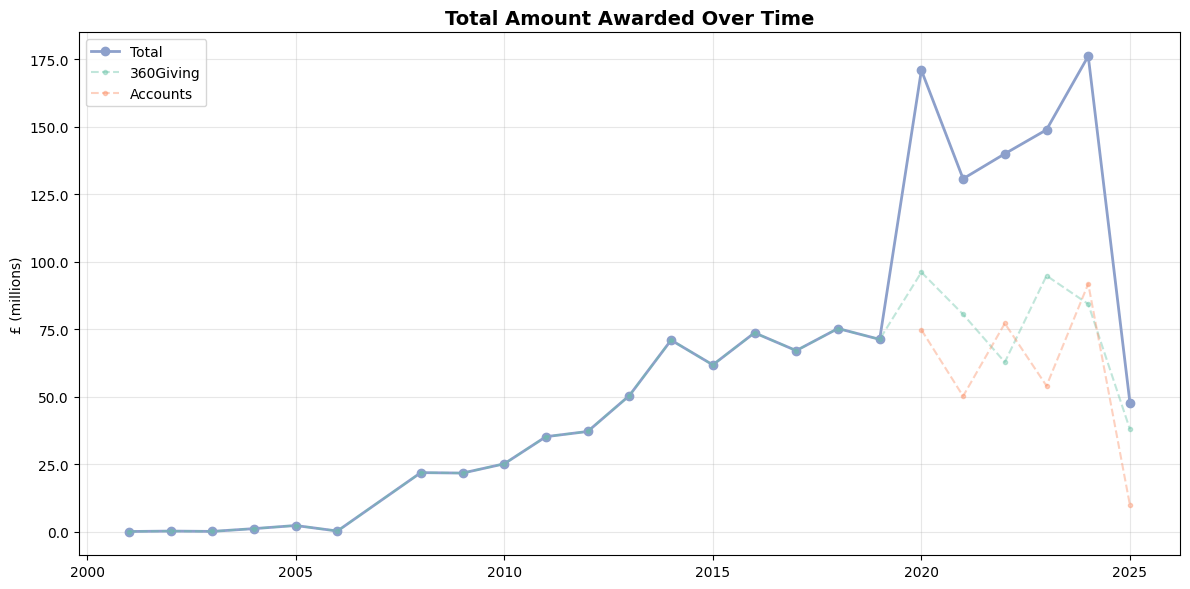
Distribution of Grants
#create boxplot
fig, ax = plt.subplots(figsize=(12, 6))
bp = ax.boxplot(data_by_year, labels=years_unique, showfliers=True)
#set log scale
ax.set_yscale("log")
ax.set_title("Distribution of Grant Values", fontsize=14, fontweight="bold")
ax.set_ylabel("Grant Value (£, log10)")
ax.grid(True, alpha=0.3, axis="y")
ax.yaxis.set_major_formatter(FuncFormatter(lambda x, p: f'£{int(x):,}'))
plt.tight_layout()
plt.show()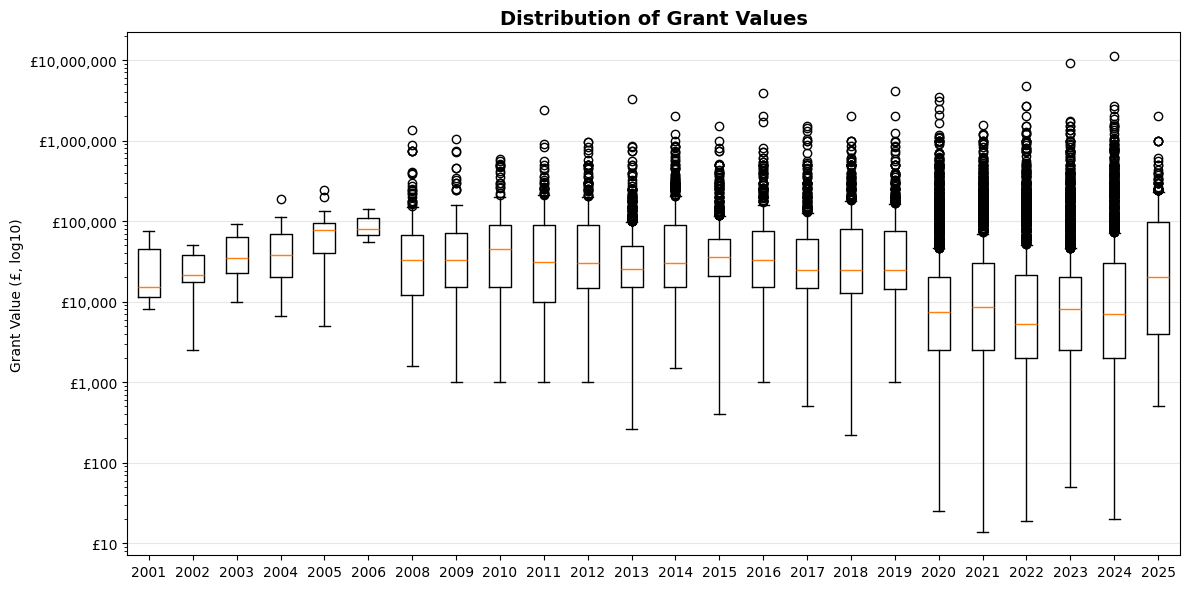
Exploration of Findings from Temporal and Financial Analysis
In the Number of Grants chart, the sharp increase from 2020 mostly reflects the data collection methodology rather than a genuine surge in grant-making - this is when the accounts data starts. Before 2020, we’re relying solely on 360Giving data which is patchier. However, the pandemic also dramatically affected grant-making, and this is the other explanatory factor for the sharp increase. The balance between the two sources shows that 360Giving provides good historical coverage back to the early 2000s, but accounts extraction is essential for capturing recent activity from funders who don’t publish to 360Giving.
In terms of giving values, there is notable year-on-year variation, with notable peaks in 2008, 2017, and 2021-22 and a general increase over time. The accounts data provides more stable coverage from 2020 onwards, but it is important to note that fluctuations in reporting (requirements) are a significant source of uncertainty. Grant values follow a log-normal distribution - most grants cluster in the £1,000-£10,000 range, but there’s a substantial tail of larger grants stretching into the hundreds of thousands.
The year-on-year consistency in the distribution suggests that typical grant sizes remain relatively stable over time, despite fluctuations in total volumes. The outliers above the whiskers represent major grants, often to large established charities or capital projects. Interestingly, the largest “grant” in the dataset was a transfer of funds from one foundation to its sister trust, representing a redistribution of assets rather than a true donation.
Exporting Dataframes back to Supabase
Table and Relationships Setup
#get final funder table
funders_table = funders_df[[
"registered_num",
"name",
"website",
"activities",
"objectives",
"achievements_performance",
"grant_policy",
"objectives_activities",
"income_latest",
"expenditure_latest",
"is_on_list",
"is_potential_sbf"
]]
#get final recipients table
recipients_table = grants_df[[
"recipient_id",
"recipient_name",
"recipient_activities"
]].drop_duplicates(subset=["recipient_id"])
#add check for cleaned recipient ids
recipients_table["has_cleaned_id"] = recipients_table["recipient_id"].isin(id_mapping["recipient_id"].values)
#get final grants table
grants_table = grants_df[[
"grant_id",
"grant_title",
"grant_desc",
"amount",
"year",
"source"
]]#dictionary to hold tables and their keys
tables = {
"funders": (funders_table, "registered_num"),
"grants": (grants_table, "grant_id"),
"recipients": (recipients_table, "recipient_id")
}Updated Recipient IDs - Join Tables
supabase = create_client(url, key)
#get old ids
old_recip_ids = id_mapping["original_recipient_id"].tolist()
if len(old_recip_ids) > 0:
#remvoe from join tables
join_tables = ["recipient_grants", "recipient_areas", "recipient_beneficiaries", "recipient_causes"]
for table in join_tables:
try:
batch_size = 100
for i in range(0, len(old_recip_ids), batch_size):
batch = old_recip_ids[i:i+batch_size]
response = supabase.table(table).delete().in_("recipient_id", batch).execute()
except Exception as e:
print(f"Error deleting from {table}: {e}")
#remove from recipients table
try:
batch_size = 100
for i in range(0, len(old_recip_ids), batch_size):
batch = old_recip_ids[i:i+batch_size]
response = supabase.table("recipients").delete().in_("recipient_id", batch).execute()
except Exception as e:
print(f"Error deleting from recipients: {e}")
print("Deletion successful")
else:
print("No IDs to clean.")Deletion successful#make dictionary to map ids and unique ids
id_map_dict = dict(zip(id_mapping["original_recipient_id"], id_mapping["recipient_id"]))
recipient_ids = set(recipients_table["recipient_id"].values)
#update all join tables
updated_recipient_grants = update_join_table(recipient_grants, id_map_dict, recipient_ids)
updated_recipient_areas = update_join_table(recipient_areas, id_map_dict, recipient_ids)
updated_recipient_causes = update_join_table(recipient_causes, id_map_dict, recipient_ids)
updated_recipient_beneficiaries = update_join_table(recipient_beneficiaries, id_map_dict, recipient_ids)
#drop helper column
recipients_table = recipients_table.drop(columns=["has_cleaned_id"])Piping Data Back to Supabase
#upsert main tables
pipe_to_supabase(funders_table, "funders", "registered_num", url, key)
pipe_to_supabase(grants_table, "grants", "grant_id", url, key)
pipe_to_supabase(recipients_table, "recipients", "recipient_id", url, key)
#upsert join tables
pipe_to_supabase(updated_recipient_grants, "recipient_grants", "recipient_grants_id", url, key)
pipe_to_supabase(updated_recipient_areas, "recipient_areas", "recipient_areas_id", url, key)
pipe_to_supabase(updated_recipient_causes, "recipient_causes", "recipient_cause_id", url, key)
pipe_to_supabase(updated_recipient_beneficiaries, "recipient_beneficiaries", "recipient_ben_id", url, key)
print("Data upserted successfully")✓ Successfully upserted all 996 records to funders
✓ Successfully upserted all 30716 records to grants
✓ Successfully upserted all 19466 records to recipients
✓ Successfully upserted all 30831 records to recipient_grants
✓ Successfully upserted all 18341 records to recipient_areas
✓ Successfully upserted all 21319 records to recipient_causes
✓ Successfully upserted all 16843 records to recipient_beneficiaries
Data upserted successfully